Chargement de fichiers GPX
Le format GPX est couramment utilisé pour stocker des données GPS, générées par une montre connectée lors d'un parcours de course par exemple. Dans ce chapitre, nous allons étudier la structure d'un tel fichier afin d'en extraire différentes informations comme la distance totale parcourue, la vitesse moyenne, jusqu'à la représentation du parcours sur une carte.
Le format XML
Le format GPX utlise la syntaxe
XML
qui permet de structurer
des informations à l'aide d'éléments délimités par des
balises (tags en anglais) ouvrante et fermante. Ci-dessous, un
extrait du fichier XML character.xml.
<?xml version="1.0" encoding="UTF-8"?>
<bigbangtheory>
<character id="46567">
<lastname>Cooper</lastname>
<firstname>Sheldon</firstname>
<gender>M</gender>
</character>
<character id="12874">
<lastname>?</lastname>
<firstname>Penny</firstname>
<gender>F</gender>
</character>
<character id="12355">
<firstname>Leonard</firstname>
<lastname>Hofstadter</lastname>
<gender>M</gender>
</character>
<character id="978776">
<lastname>Wolowitz</lastname>
<firstname>Howard</firstname>
<gender>M</gender>
</character>
<character id="34345">
<gender>M</gender>
<firstname>Raj</firstname>
<lastname>Koothrappali</lastname>
</character>
</bigbangtheory>
Ce fichier recense les personnages principaux de la série américaine
Big Bang Theory.
Vous remarquerez que les informations
sont organisées sous la forme d'une arborescence traduite par l'imbrication des
éléments : l'élément racine bigbangtheory contient plusieurs
éléments enfants character. Chaque élément enfant peut lui-même
contenir des enfants (lastname, firstname et gender
dans ce cas précis).
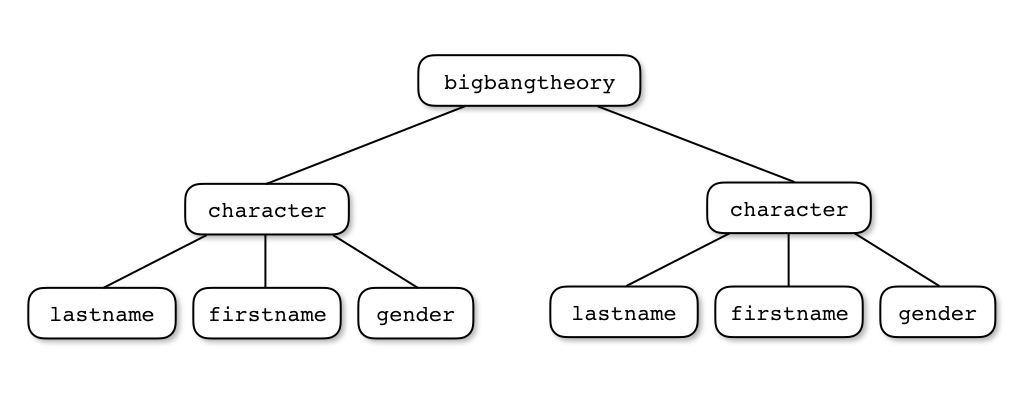
Ainsi, le contenu d'un élément délimité par une balise ouvrante <tagname>
et une balise fermante </tagname> peut être :
- Une liste d'éléments enfants
- Un texte (par exemple
Fpour l'élémentgender)
Un attribut peut aussi être associé à un élément : il apparaît dans la balise ouvrante
sous la forme d'un couple (clé,valeur). Dans notre exemple, chaque élément character
dispose d'un attribut id.
Le module beautifulsoup4
La structure d'un fichier XML étant plus complexe que celle d'un fichier CSV, nous allons nous
appuyer sur le module
beautifulsoup4
pour parcourir le contenu du fichier afin d'en extraire
certaines informations. Comme tous les modules externes, il doit être installé avant d'être utilisé.
La commande sous Windows est la suivante :
pip.exe install beautifulsoup4 lxmlEt sous macOS ou Linux
pip3 install beautifulsoup4 lxml
Un fois le module importé dans le script, on charge le contenu du fichier XML en mémoire
à l'aide de la fonction open() et on construit l'arborescence des données
avec la fonction BeautifulSoup().
from bs4 import BeautifulSoup as bs
# Chargement du fichier XML
content = open('character.xml')
# Construction de l'arborescence
root = bs(content, features='xml')
Extraction d'informations
la méthode find_all() permet de rechercher un élément dans
l'arborescence des données XML afin d'extraire une information particulière.
Par exemple, le code ci-dessous permet d'afficher les prénoms de tous les personnages.
from bs4 import BeautifulSoup as bs
# Chargement du fichier XML
content = open('character.xml')
# Construction de l'arborescence
root = bs(content, features='xml')
for tag in root.find_all('firstname'):
print(tag.string)
La recherche est effectuée à partir de la racine de l'arborescence afin
d'extraire tous les éléments firstname, enfant d'un élément character lui-même
enfant de l'élément bigbangtheory.
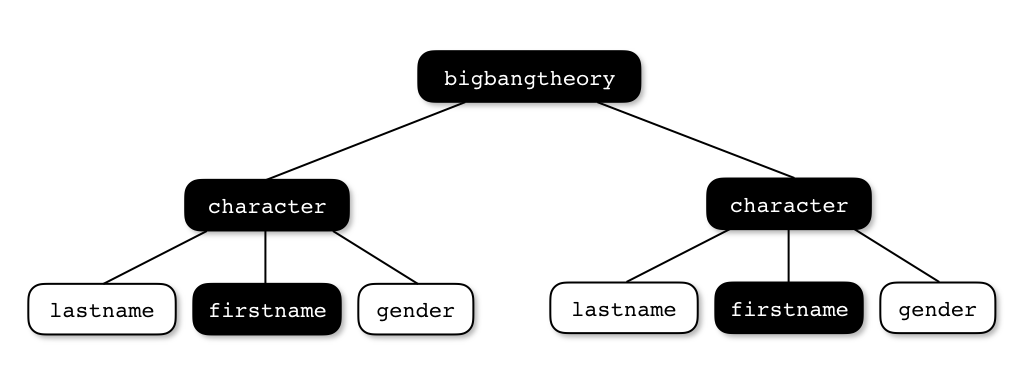
firstname
L'accès à la valeur d'un attribut associé à un élément se fait via l'opérateur [ ].
Le script suivant affiche les identifiants de tous les personnages.
from bs4 import BeautifulSoup as bs
# Chargement du fichier XML
content = open('character.xml')
# Construction de l'arborescence
root = bs(content, features='xml')
for tag in root.find_all('character'):
print(tag['id'])
Enfin, lorsque l'on a besoin d'accéder à plusieurs valeurs au sein d'un élément,
il est possible d'appeler la méthode find() à partir de l'élément courant
afin d'effectuer une recherche locale parmi ses enfants. Le script ci-dessous
affiche l'identifiant ainsi que le nom et le prénom de chaque personnage :
from bs4 import BeautifulSoup as bs
content = open('character.xml')
root = bs(content, features='xml')
print('\n\n+ Liste des personnages principaux :')
for tag in root.find_all('character'):
id = tag['id']
# Recherches à partir de l'élément character
# afin d'extraire les valeurs des enfants
lastname = tag.find('lastname').string
firstname = tag.find('firstname').string
print('(', id, ')', lastname, firstname)Exercice
Modifiez le script précédent afin de calculer la proportion de personnages féminins et masculins dans Big Bang Theory.
+ Liste des personnages principaux :
( 46567 ) Cooper Sheldon
( 12874 ) ? Penny
( 12355 ) Hofstadter Leonard
( 978776 ) Wolowitz Howard
( 34345 ) Koothrappali Raj
( 75543 ) Bloom Stuart
( 65238 ) Fowler Amy Farrah
( 45984 ) Rostenkowski Bernadette
( 17360 ) Jeffries Arthur
( 91727 ) Kripke Barry
( 12757 ) Winkle Leslie
( 761289 ) Sweeney Emily
( 13247 ) Winkle Leslie
( 97852 ) Koothrappali Priya
( 57689 ) Wheaton Wil
( 91557 ) Gibbs Dave
( 836411 ) Barnett Stephanie
+ Proportion d'hommes et de femmes :
Femmes : 47%
Hommes : 53%from bs4 import BeautifulSoup as bs
content = open('character.xml')
root = bs(content, features='xml')
female_count = 0
male_count = 0
print('\n\n+ Liste des personnages principaux :')
for tag in root.find_all('character'):
id = tag['id']
lastname = tag.find('lastname').string
firstname = tag.find('firstname').string
gender = tag.find('gender').string
if gender == 'F':
female_count = female_count + 1
else:
male_count = male_count + 1
print('(', id, ')', lastname, firstname)
character_count = female_count + male_count
print('\n\n+ Proportion d\'hommes et de femmes :')
print('Femmes :', round(female_count*100/character_count), '%')
print('Hommes :', round(male_count*100/character_count), '%\n\n')Le format GPX
Maintenant que nous nous sommes familiarisés avec le format XML et les méthodes du module
beautifulsoup4,
il est temps de disséquer un fichier GPX contenant des relevés GPS. Je vous propose de commencer avec
un extrait du fichier RATJ2012-21km-herve.schely.gpx.
<?xml version="1.0" encoding="UTF-8"?>
<gpx version="1.1"
creator="runtastic - makes sports funtastic, http://www.runtastic.com"
xsi:schemaLocation="http://www.topografix.com/GPX/1/1
http://www.topografix.com/GPX/1/1/gpx.xsd
http://www.garmin.com/xmlschemas/GpxExtensions/v3
http://www.garmin.com/xmlschemas/GpxExtensionsv3.xsd
http://www.garmin.com/xmlschemas/TrackPointExtension/v1
http://www.garmin.com/xmlschemas/TrackPointExtensionv1.xsd"
xmlns="http://www.topografix.com/GPX/1/1"
xmlns:gpxtpx="http://www.garmin.com/xmlschemas/TrackPointExtension/v1"
xmlns:gpxx="http://www.garmin.com/xmlschemas/GpxExtensions/v3"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<metadata>
<copyright author="www.runtastic.com">
<year>2012</year>
<license>http://www.runtastic.com</license>
</copyright>
<link href="http://www.runtastic.com">
<text>runtastic</text>
</link>
<time>2012-10-21T07:01:38.000Z</time>
</metadata>
<trk>
<link href="http://www.runtastic.com/sport-sessions/29614704">
<text>Cliquez sur ce lien pour voir cette activité sur runtastic.com</text>
</link>
<trkseg>
<trkpt lon="4.0281324386596697" lat="49.2516021728515980">
<ele>82.0</ele>
<time>2012-10-21T07:01:39.000Z</time>
</trkpt>
<trkpt lon="4.0278654098510698" lat="49.2515068054199006">
<ele>82.0</ele>
<time>2012-10-21T07:01:52.000Z</time>
</trkpt>
<trkpt lon="4.0278654098510698" lat="49.2515068054199006">
<ele>82.0</ele>
<time>2012-10-21T07:02:12.000Z</time>
</trkpt>
</trkseg>
</trk>
</gpx>Exercice
Après avoir étudié minutieusement la structure du fichier d'exemple, écrivez un script gpxplorer.py
qui remplit un DataFrame composé des colonnes ['datetime', 'latitude', 'longitude', 'elevation']
à partir des données contenues dans l'arborescence XML.
from bs4 import BeautifulSoup as bs
import pandas as pd
df = pd.DataFrame([], columns = [ 'datetime', 'latitude', 'longitude', 'elevation' ])
# Chargement du fichier GPX
content = open('RATJ2012-21km-herve.schely.gpx')
# Construction de l'arborescnce
root = bs(content, features='xml')
k = 0
for point in root.find_all('trkpt'):
df.loc[k, 'datetime'] = point.find('time').string
df.loc[k, 'latitude'] = float(point['lat'])
df.loc[k, 'longitude'] = float(point['lon'])
df.loc[k, 'elevation'] = float(point.find('ele').string)
k = k + 1
df.to_excel('RATJ2012-21km-herve.schely.xlsx', index=False)
Dans le chapitre Visualisation de trajectoires, nous avons appris
à créer des graphiques à l'aide des modules matplotlib et plotly.
Exercice
Modifiez le scriptgpxplorer.py afin de générer les deux graphiques ci-dessous.
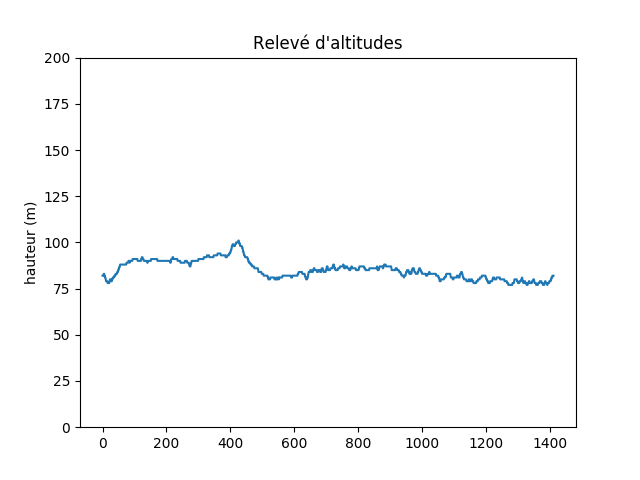
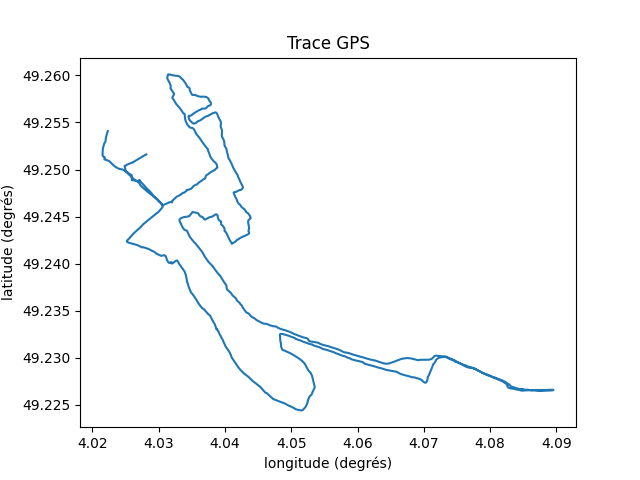
from bs4 import BeautifulSoup as bs
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame([], columns = [ 'datetime', 'latitude', 'longitude', 'elevation' ])
# Chargement du fichier GPX
content = open('RATJ2012-21km-herve.schely.gpx')
# Construction de l'arborescnce
root = bs(content, features='xml')
k = 0
for point in root.find_all('trkpt'):
df.loc[k, 'datetime'] = point.find('time').string
df.loc[k, 'latitude'] = float(point['lat'])
df.loc[k, 'longitude'] = float(point['lon'])
df.loc[k, 'elevation'] = float(point.find('ele').string)
k = k + 1
df.to_excel('RATJ2012-21km-herve.schely.xlsx', index=False)
plt.plot(df['elevation'])
plt.ylim(0, 200)
plt.title('Relevé d\'altitudes')
plt.ylabel('hauteur (m)')
plt.show()
plt.plot(df['longitude'], df['latitude'])
plt.title('Trace GPS')
plt.xlabel('longitude (degrés)')
plt.ylabel('latitude (degrés)')
plt.show()Pour évaluer des distances à partir de couples (latitude, longitude), nous allons avoir besoin de quelques rudiments de trigonométrie, c'est justement l'objet du prochain chapitre.