Utilisation d'APIs
Le World Wide Web regorge de données, encore faut-il savoir y accéder. Les APIs (Application Programming Interface) Web exposent des informations de natures diverses qui peuvent être extraites selon différents critères.
Une API Web se présente sous la forme d'une adresse internet (i.e. URL) et de suffixes (endpoints en anglais) pour chaque type de ressource accessible via l'API.
Afin d'illustrer cette notion d'interface de données, j'ai ponctué ce cours d'exemples progressifs en m'appuyant sur une API essentielle, à savoir The Internet Chuck Norris Database recensant les blagues relatives au légendaire Chuck Norris.
https://api.chucknorris.io/jokes/random
Dans l'exemple ci-dessus, https://api.chucknorris.io correspond à l'URL de
l'API et /jokes/random est un des endpoints disponibles.
Always wanted to be #ChuckNorris : my dream came true with @reface_app #deepfake pic.twitter.com/HTXjeHYii1
— Olivier Nocent (@oliviernocent) November 6, 2020
Le module requests
Ce module facilite les interactions avec une API Web en permettant de formuler des requêtes et d'exploiter les réponses retournées par le serveur.
Un module vient compléter le jeu d'instructions de base du langage Python. Il doit donc être installé avant d'être utilisé. La commande sous Windows est la suivante :
pip.exe install requestsEt sous Linux ou macOS
pip3 install requestsInterrogation de l'API
Une API Web repose sur le protocole HTTP,
un protocole de communication pour l'échange de données sur le Web. La fonction get()
du module requests permet de formuler une requête HTTP en utilisant la méthode
GET.
import requests
# Envoi d'une requête HTTP en méthode GET
response = requests.get('https://api.chucknorris.io/jokes/random')Utilisation de la réponse
En mode synchrone, l'interprète Python attend la réponse de l'API
avant de continuer l'exécution du script. Le résultat stocké dans
la variable response peut ainsi être exploité dans la
suite du code source.
Code d'état HTTP
import requests
response = requests.get('https://api.chucknorris.io/jokes/random')
print(response.status_code)
La variable response contient un attribut
status_code qui correspond au code d'état
HTTP retourné par le serveur.
| Code | Message |
|---|---|
| 200 | OK |
| 403 | Forbidden |
| 404 | Not Found |
| 418 | I'm a teapot |
| 500 | Internal Server Error |
| 503 | Service Unavailable |
Ce code d'état permet de s'assurer que les données de la réponse ont bien été acheminées et, dans le cas contraire, de diagnostiquer le problème. La liste exhaustive des codes d'état HTTP est consultable en ligne.
Données au format JSON
JSON (JavaScript Object Notation) est une représentation de données arborescentes plus concise que le format XML. La requête
https://api.chucknorris.io/jokes/randomretourne la réponse ci-dessous
{
"icon_url" : "https://assets.chucknorris.host/img/avatar/chuck-norris.png",
"id" : "Ngdqg6LKTqedxJC8pkV6Bg",
"url" : "",
"value": "Nothing can escape the gravity of a black hole, except for Chuck Norris. Chuck Norris eats black holes. They taste like chicken."
}
Les accolades { } délimitent un objet décrit par des couples clé/valeur.
Dans notre exemple, la clé id a pour valeur Ngdqg6LKTqedxJC8pkV6Bg.
Mais une valeur peut elle-même être un objet d'où la nature arborescente (i.e. hiérarchique)
des données représentées par le format JSON.
Une autre requête
https://api.chucknorris.io/jokes/categoriesretourne une réponse de la forme suivante
[
"animal",
"career",
"celebrity",
"dev",
"explicit",
"fashion",
"food",
"history",
"money",
"movie",
"music",
"political",
"religion",
"science",
"sport",
"travel"
]
Les crochets [ ] délimitent une liste de valeurs qui
peuvent être des objets contenant des couples clé/valeur.
La méthode json() retourne le contenu JSON de la réponse sous la forme
d'une variable de type dict, un dictionnaire Python basé sur le
concept clé/valeur. L'accès à une valeur du dictionnaire se fait avec l'opérateur
[ ] en précisant le nom de la clé associée.
import requests
response = requests.get('https://api.chucknorris.io/jokes/random')
if response.status_code == 200:
data = response.json()
print('\n\nJoke of the day:\n')
print(data['value'], '\n')
Joke of the day:
An anagram for Walker Texas Ranger is KARATE WRANGLER SEX. I don't know what it is, but it sounds awesome.
Lorsque la réponse contient une liste d'objets, le script Python peut
les parcourir à l'aide d'une boucle for.
import requests
response = requests.get('https://api.chucknorris.io/jokes/categories')
if response.status_code == 200:
data = response.json()
print(len(data), 'categories:')
for category in data:
print(category)16 categories:
animal
career
celebrity
dev
explicit
fashion
food
history
money
movie
music
political
religion
science
sport
travelRequête HTTP avec paramètres
Une API Web autorise certains paramètres afin de filtrer les résultats. Ces paramètres
répondent au même modèle clé/valeur. Dans notre exemple, elle autorise le paramètre
category afin de restreindre le tirage aléatoire d'une blague de Chuck Norris
à une seule catégorie.
import requests
parameters = {
'category': 'music'
}
# l'URL devient https://api.chucknorris.io/jokes/random?category=music
response = requests.get('https://api.chucknorris.io/jokes/random', params=parameters)
if response.status_code == 200:
data = response.json()
print('Joke of the day:\n')
print(data['value'], '\n')Joke of the day:
Chuck Norris can touch MC Hammer.
Après cette brève introduction au fonctionnement des APIs Web, il est temps de développer vos propres projets. Pour démarrer, je vous recommande The Public API for Public APIs
balldontlie API
Je dois vous faire une confession : je n'ai pas conçu manuellement, ligne après ligne, les fichiers Excel de la saison NBA 2018-2019 du chapitre précédent. J'ai utilisé l'API balldontlie. Je vous propose de nous y attarder afin d'apprendre à interagir avec une API plus complexe qui propose des données paginées, à savoir des données volumineuses qui nécessitent plusieurs requêtes pour les consulter dans leur intégralité.
La section Get All
Active Players de la documentation décrit l'utilisation du endpoint
/players permettant de consulter l'ensemble des joueurs, actifs ou retraités, renseignés dans la
base de données balldontlie.
Exercice
En étudiant la structure de la réponse retournée par le endpoint
/players, écrivez un script Python affichant les noms des 25
premiers joueurs.
import requests
key = { 'Authorization': 'YOUR_API_KEY' }
response = requests.get('https://api.balldontlie.io/v1/players', headers = key)
if response.status_code == 200:
data = response.json()
print('NBA players:')
for player in data['data']:
print(player['first_name'], player['last_name'])
Les données, relativement volumineuses, sont retournées sous forme de
pages dont la taille peut être définie par l'utilisateur grâce au paramètre
per_page.
https://api.balldontlie.io/v1/players/active?per_page=50
Avec le module requests, il est possible de transmettre ces paramètres à la méthode
get() sous la forme d'un dictionnaire Python.
import requests
key = { 'Authorization': 'YOUR_API_KEY' }
parameters = { 'per_page': 50 }
response = requests.get('https://api.balldontlie.io/v1/players', headers = key, params = parameters)Exercice
Complétez votre script Python en demandant à récupérer 100 joueurs par page.
import requests
key = { 'Authorization': 'YOUR_API_KEY' }
parameters = { 'per_page': 100}
response = requests.get('https://api.balldontlie.io/v1/players', headers = key, params = parameters)
if response.status_code == 200:
data = response.json()
print('NBA players:')
for player in data['data']:
print(player['first_name'], player['last_name'])
else:
print('Error', response.status_code, response.reason)
Afin de récupérer l'intégralité des informations disponibles sur les joueurs, il
est nécessaire d'interroger chacune des pages disponibles. Cette action peut être
automatisée à l'aide d'une boucle qui met à jour une variable transmise à l'API via
le paramètre cursor.
Exercice
Complétez à nouveau votre script Python afin d'intégrer un boucle qui effectuera une requête pour chaque page disponible. Les informations extraites de chaque réponse seront stockées dans un DataFrame composé des colonnes suivantes :
- lastname
- Nom de famille du joueur
- firstname
- Prénom du joueur
- height (m)
- Taille, convertie en mètres, du joueur
- weight (kg)
- Poids, converti en kilogrammes, du joueur
- team
- Nom complet de l'équipe NBA
- jersey_number
- Numéro de dossard
- position
- Poste du joueur
import pandas as pd
import requests
import time
df = pd.DataFrame([],
columns=['lastname', 'firstname', 'height (m)', 'weight (kg)', 'team', 'jersey_number', 'position'])
key = {'Authorization': 'YOUR_API_KEY'}
p = {'per_page': 100, 'cursor': 0}
k = 0
while True:
response = requests.get('https://api.balldontlie.io/v1/players',
headers=key, params=p)
if response.status_code == 200:
data = response.json()
for player in data['data']:
if player['height'] != None and player['weight'] != None:
i = player['height'].find('-')
feet = float(player['height'][:i])
inches = float(player['height'][i+1:])
df.loc[k, 'lastname'] = player['last_name']
df.loc[k, 'firstname'] = player['first_name']
df.loc[k, 'height (m)'] = round(feet * 0.3048 + inches * 0.0254, 2)
df.loc[k, 'weight (kg)'] = round(float(player['weight']) * 0.453592)
df.loc[k, 'team'] = player['team']['full_name']
df.loc[k, 'jersey_number'] = player['jersey_number']
df.loc[k, 'position'] = player['position']
k = k + 1
if 'next_cursor' in data['meta']:
p['cursor'] = data['meta']['next_cursor']
time.sleep(3)
else:
break
else:
print('Error', response.status_code, response.reason)
df.to_excel('NBA.xlsx', sheet_name='players', index = False)À partir du fichier Excel généré avec les données issues de l'API, il est possible de calculer quelques statistiques.
Exercice
Écrivez un script Python qui, après chargement du fichier Excel, calcule la moyenne et l'écart-type de la taille et du poids des joueurs et génère le graphique ci-dessous.
import pandas as pd
import plotly.express as px
df = pd.read_excel('NBA.xlsx')
mean_height = round(df['height (m)'].mean(), 2)
std_height = round(df['height (m)'].std(), 2)
print('Height: ', mean_height, '-/+', std_height, 'm')
mean_weight = round(df['weight (kg)'].mean(), 1)
std_weight = round(df['weight (kg)'].std(), 1)
print('Weight: ', mean_weight, '-/+', std_height, 'kg')
fig = px.scatter(df, x='weight (kg)', y='height (m)', color='position', hover_data=['firstname', 'lastname'], title='NBA players anthropometry')
fig.show()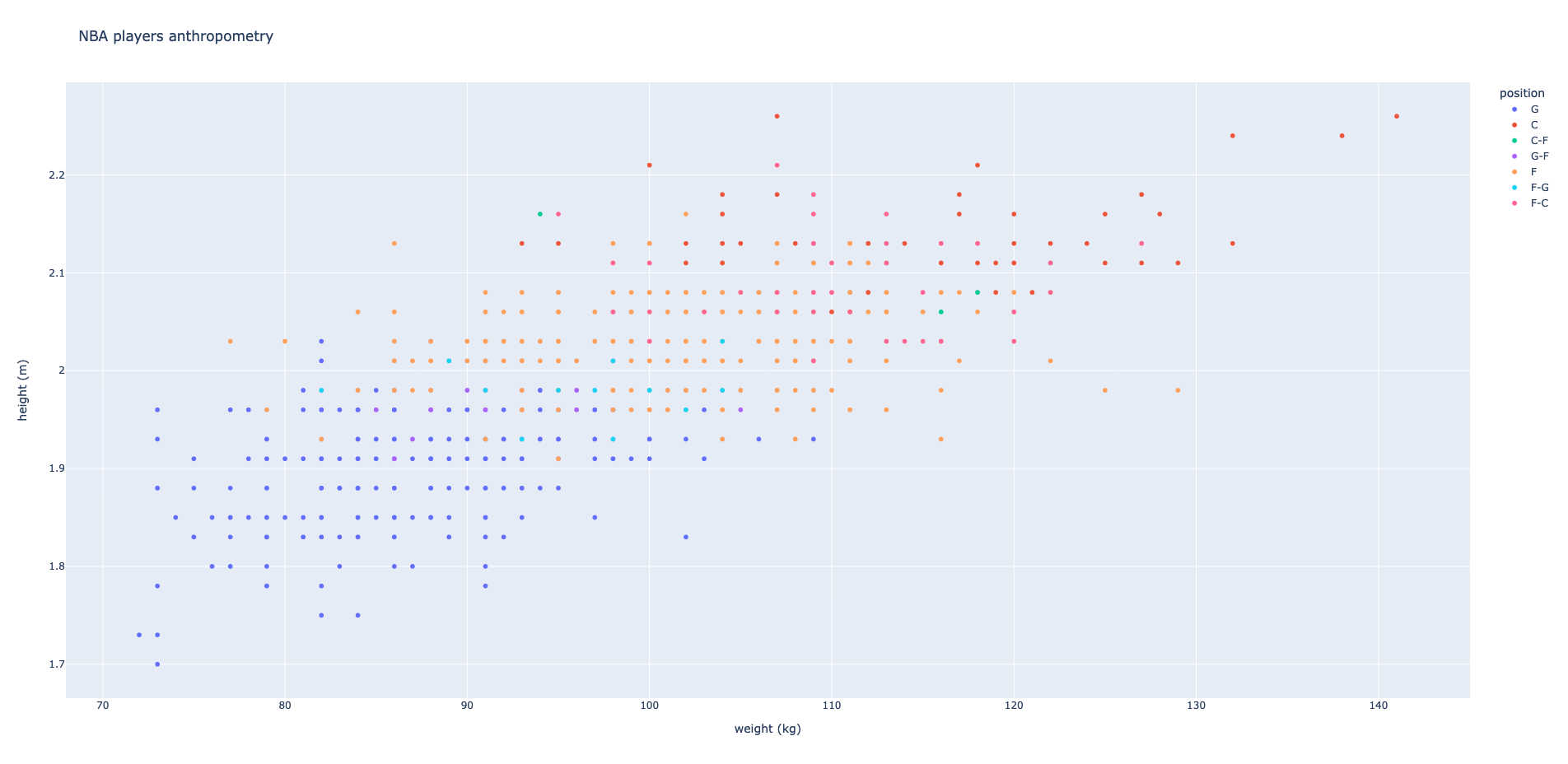
RESPIRE
Respire, et si ça te suffit pas re-respire
Ou bien le pire est à venir bébé
Augmente le débit, yéyéyé
Tout le monde dans la place fait yéyéyé
Pour changer de thème, je vous propose une activité visant à produire une cartographie de la qualité de l'air à partir des données fournies par Open AQ Platform.
La section Measurements de la documentation décrit les paramètres autorisés afin d'extraire des concentrations géolocalisées de certains polluants.
Exercice
Identifiez les paramètres à utiliser afin d'extraire les concentrations d'ozone (O3) en France pour la journée du 1er novembre 2021.
| Paramètre | Valeur |
|---|---|
country |
FR |
parameter |
o3 |
date_from |
2021-11-01 |
date_to |
2021-11-02 |
limit |
1000 |
Même si les données de l'API sont paginées, l'ensemble des mesures d'une journée sur le territoire
français peuvent être récupérées en une seule requête en fixant le paramètre limit à sa valeur
maximale, à savoir 1000.
Exercice
Écrivez un script Python respire.py qui effectue une requête auprès de l'API OpenAQ
afin d'afficher les concentrations d'ozone ainsi que les coordonnées GPS des relevés sur le territoire
français pour la journée du 1er novembre 2021.
import requests
parameters = {
'country': 'FR',
'parameter': 'o3',
'date_from': '2021-11-01',
'date_to': '2021-11-02',
'limit': 1000
}
response = requests.get('https://api.openaq.org/v2/measurements', params=parameters)
if response.status_code == 200:
data = response.json()
for measure in data['results']:
print(measure['value'], measure['coordinates']['latitude'], measure['coordinates']['longitude'])
Les relevés géolocalisés peuvent aisément être affichés sur une carte avec l'aide du module
folium sous la forme de marqueurs.
Exercice
Complétez votre script Python respire.py afin d'initialiser une carte sur laquelle vous
ajouterez un marqueur pour chaque relevé de polluant. La couleur du marqueur pourrait changer en fonction
de la concentration, conformément aux standards de la qualité de l'air proposés
par la Commission européenne.
import requests
import folium
# Création d'une carte centrée sur Clermont Ferrand
fmap = folium.Map(location=[45.7833, 3.0833], tiles="Stamen Terrain", zoom_start=6)
parameters = {
'country': 'FR',
'parameter' : 'o3',
'date_from': '2021-11-01T00:00:00',
'date_to': '2021-11-02T00:00:00',
'limit': 1000
}
response = requests.get('https://api.openaq.org/v2/measurements', params=parameters)
if response.status_code == 200:
data = response.json()
print(data['meta']['found'], 'relevés trouvés...')
for measure in data['results']:
col = 'lightblue'
if measure['value']>=120:
col='darkpurple'
elif measure['value']>=100:
col='purple'
elif measure['value']>=80:
col='red'
elif measure['value']>=60:
col='lightred'
elif measure['value']>=40:
col='orange'
elif measure['value']>=20:
col='lightgreen'
'''
# Solution astucieuse proposée par Jonathan RAHARINDRANTO (M2 IEAP, UFR STAPS Reims)
lookup_table = ['lightblue', 'lightgreen', 'orange', 'lightred', 'red', 'purple', 'darkpurple']
col = lookup_table[ min(6, int(measure['value']/20)) ]
'''
# Ajout d'un marqueur
folium.Marker([ measure['coordinates']['latitude'], measure['coordinates']['longitude'] ],
popup=str(measure['value']) + ' ' + measure['unit'],
icon=folium.Icon(color=col)).add_to(fmap)
# Génération du fichier HTML contenant la carte
fmap.save("2021-11-01-FR-O3.html")En chargeant le fichier HTML dans votre navigateur Web, vous avez dû constater que l'interaction avec la carte n'est pas fluide en raison du nombre trop important de marqueurs. Il existe d'autres modalités pour visualiser des données géolocalisées. Une heat map est une représentation graphique de données spatiales à l'aide d'un dégradé de couleurs.
La fonction HeatMap disponible dans les
plugins
du module folium permet de superposer cette représentation graphique des données
numériques sur un fond de carte.
Exercice
Écrivez un nouveau script Python respire_hm.py où les marqueurs seront remplacés
par une heat map.
import requests
import folium
from folium.plugins import HeatMap
# Création d'une carte
fmap = folium.Map(location=[45.7833, 3.0833], tiles="Stamen Terrain", zoom_start=7)
parameters = {
'country': 'FR',
'parameter' : 'o3',
'date_from': '2021-11-01T00:00:00',
'date_to': '2021-11-02T00:00:00',
'limit': 1000
}
response = requests.get('https://api.openaq.org/v2/measurements', params=parameters)
if response.status_code == 200:
data = response.json()
print(data['meta']['found'], 'relevés trouvés...')
measure_list = []
for measure in data['results']:
measure_list.append( [ measure['coordinates']['latitude'], measure['coordinates']['longitude'], measure['value'] ] )
HeatMap(data=measure_list).add_to(fmap)
# Génération du fichier HTML contenant la carte
fmap.save("2021-11-01-FR-O3-hm.html")