Projet individuel
Objectifs et déroulé
Une partie des séances de TD sera consacrée au développement d'un projet Big Data individuel. Ce projet devra faire appel à l'ensemble des notions développés dans les séances de CM et donnera lieu à un rapport écrit et une présentation devant l'ensemble du groupe lors de la dernière séance de TD.
Il est demandé que l'ensemble des items énoncés plus loin soit abordé et traité, mais il est admis qu'en fonction des parcours (Calcul Scientifique, Sciences Economiques, Statistique) certains parties du projet puissent être développées de façon plus approfondie que d'autres. Le choix de l'environnement (langage, logiciel, ...) pour la partie implantation ou expérimentation réelle est libre, notamment.
Évaluation
Le rendu du projet consistera en :
- un rapport écrit ;
- du code implantant une partie ou la totalité du traitement des données décrit dans le rapport, considérant que ce code devra intégrer une composante de calcul réparti ;
- une soutenance orale avec support visuel.
La totalité des documents produits devra être disponible sur un dépot git.
L'évaluation portera sur :
- l'exactitude et pertinence des propos,
- la qualité de l'argumentation,
- la qualité et la pertinence du code produit,
- la fluidité et clarté de la présentation.
Les rendus pourront être en français ou en anglais. La maîtrise syntaxique de la langue ne sera pas un critère d'évaluation.
Consignes
Le projet consistera à sélectionner une application spécifique de la façon la plus détaillée et aboutie possible.
Les livrables du projet aborderont les points énumérés ci-dessous.
- Choix d'un contexte applicatif : quelles données, à quelle finalité, motivation économique ou sociétale (une bon point de départ consiste à trouver des donnés ouvertes et publiques, comme, par exemple ici);
- Origine, volumétrie et format des données ;
- Contraintes techniques d'accès aux données, de disponibilité, sécurisation, garanties de qualité et de cohérence ;
- Code permettant de mettre les données au bon format, de les traiter de façon efficace, notamment en intégrant les contraintes d'accès aux données s'il y en a (concurrence d'accès, gestion de la cohérence ou des conflits, découpage en lots ...) ou de traitement (Spark, Map-Reduce...) ;
- Analyse des difficultés techniques et des résultats obtenus.
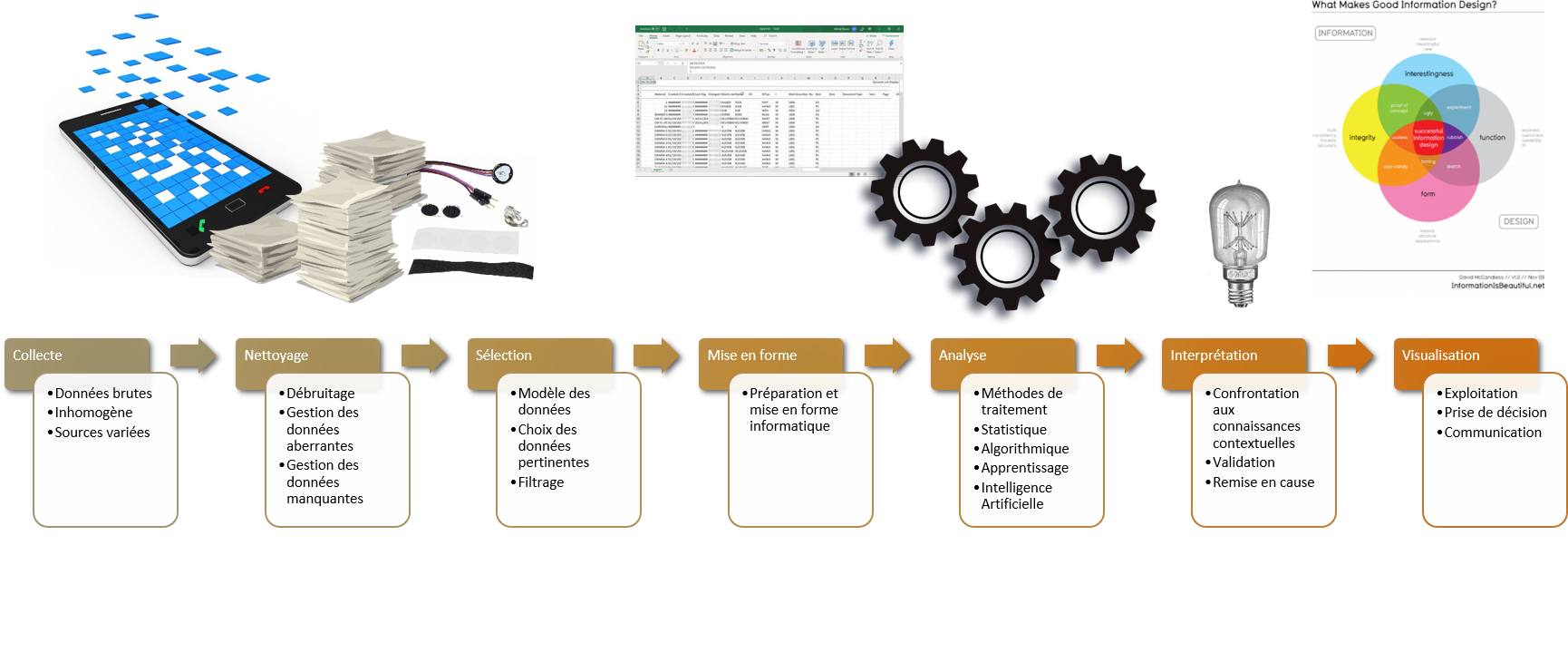
Idéalement, l'ensemble des étapes présentées en cours, et représentées dans l'illustration ci-dessous devraient être abordées (ou du moins mentionnées)