Comparaison entre listes et tableaux
Comparaison des coûts
Rappel : les collections sont triées. Cette information doit être utilisée dans le calcul des coûts !
1. Coût de recherche
Nous voulons chercher un élément dans une collection, ce qui est, dans notre cas, similaire à savoir si l'élément est présent.
Meilleur cas
Pour chacune des structures (tableau et liste) trouvez une configuration (contenu de la collection, caractéristiques de l'élément à trouver) qui amène à faire le moins d'opérations. Exprimez ce nombre d'opérations en fonction de la taille n de la collection.
Par exemple, que se passe-t-il si on cherche la valeur 15 dans les listes suivantes, selon la structure de stockage ?
[ 0, 5, 10, 15, 20, 25, 30 ]
[ 15, 30, 45, 60, 75 ]
Pire cas
Pour chacune des structures (tableau et liste) trouvez une configuration (contenu de la collection, caractéristiques de l'élément à trouver) qui amène à faire le plus d'opérations. Exprimez ce nombre d'opérations en fonction de la taille n de la collection.
Par exemple, que se passe-t-il si on cherche la valeur 10 dans les listes suivantes, selon la structure de stockage ?
[ 0, 5, 10, 15, 20, 25, 30 ]
[ 2, 4, 6, 8, 10 ]
Evaluation empirique
En utilisant le code fourni en début de ce document, basé sur ProfileRunner évaluez empiriquement le coût de recherche dans les deux types de structure.
Évaluez les temps d'exécution avec différentes tailles de liste pour observer les courbes et leur évolution en fonction de la taille de la collection.
Vous pouvez vous baser sur le code suivant (relatif aux tableaux, et que vous adapterez pour les listes également).
# Mettre les import appropriés
def gen_tableau_n(n: int):
data = ProfileRunner.gen_intList(n)
setstructure(TableauTrie())
for i in data:
getstructure().insert(i)
return data
if __name__ == '__main__':
pr = PlotPerf.ProfileRunner()
pr.addFunction(test_contains, gen_tableau_n)
pr.runProfiler(range(1, 3000, 50), correct=lambda v, n: v/n)
pr.plotResults()
plt.show()
Est-ce que les courbes des temps d'exécution observés sont conformes à la théorie ?
2. Coût d'insertion
Nous voulons insérer un nouvel élément dans la collection. On rappelle qu'après insertion, la collection doit rester triée.
Meilleur cas
Pour chacune des structures (tableau et liste) trouvez une configuration (contenu de la collection, caractéristiques de l'élément à trouver) qui amène à faire le moins d'opérations. Exprimez ce nombre d'opérations en fonction de la taille n de la collection.
Pire cas
Pour chacune des structures (tableau et liste) trouvez une configuration (contenu de la collection, caractéristiques de l'élément à trouver) qui amène à faire le plus d'opérations. Exprimez ce nombre d'opérations en fonction de la taille n de la collection.
Évaluation empirique
En utilisant le code fourni en début de ce document, basé sur ProfileRunner évaluez empiriquement le coût d'insertion dans les deux types de structure.
Évaluez les temps d'exécution avec différentes tailles de liste pour observer les courbes et leur évolution en fonction de la taille de la collection.
Vous pouvez vous baser sur le code suivant (relatif aux tableaux, et que vous adapterez pour les listes également)
# Mettre les import appropriés
def test_insertion_tableau(donnees):
setstructure(TableauTrie())
test_insertion(donnees)
setstructure(None)
if __name__ == '__main__':
pr = PlotPerf.ProfileRunner()
pr.addFunction(test_insertion_tableau, PlotPerf.gen_intList)
pr.runProfiler(range(1, 3000, 50), correct=lambda v, n: v/n)
pr.plotResults()
plt.show()
3. Coût de suppression
Nous voulons supprimer un élément de la collection. On rappelle qu'après suppression, la collection doit rester triée.
Meilleur cas
Pour chacune des structures (tableau et liste) trouvez une configuration (contenu de la collection, caractéristiques de l'élément à trouver) qui amène à faire le moins d'opérations. Exprimez ce nombre d'opérations en fonction de la taille n de la collection.
Pire cas
Pour chacune des structures (tableau et liste) trouvez une configuration (contenu de la collection, caractéristiques de l'élément à trouver) qui amène à faire le plus d'opérations. Exprimez ce nombre d'opérations en fonction de la taille n de la collection.
Évaluation empirique
En utilisant le code fourni en début de ce document, basé sur ProfileRunner évaluez empiriquement le coût de suppression dans les deux types de structure.
Évaluez les temps d'exécution avec différentes tailles de liste pour observer les courbes et leur évolution en fonction de la taille de la collection.
# Mettre les import appropriés
def gen_tableau_n(n: int):
data = ProfileRunner.gen_intList(n)
setstructure(TableauTrie())
for i in data:
getstructure().insert(i)
return data
if __name__ == '__main__':
pr = PlotPerf.ProfileRunner()
pr.addFunction(test_delete, gen_tableau_n)
pr.runProfiler(range(1, 3000, 50), correct=lambda v, n: v/n)
pr.plotResults()
plt.show()
Résultats attendus
En conclusion, on doit observer qu'une collection triée a une complexité linéaire en n (sa taille) pour l'insertion
et la suppression, et une complexité logarithmique en recherche lorsqu'elle est codée en structure tabulaire.
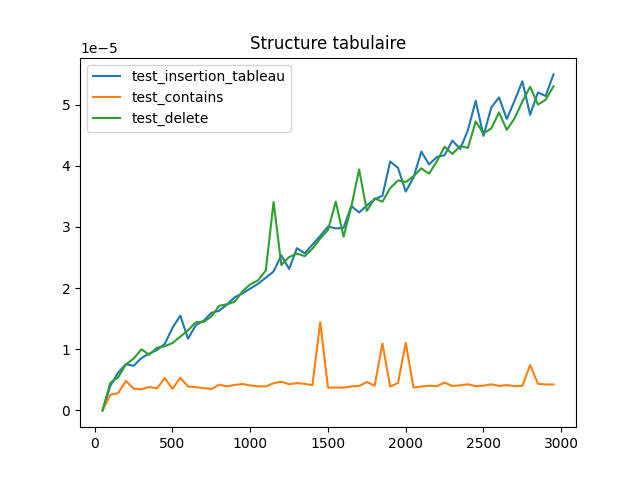
On observe que cette même triée a une complexité linéaire en n (sa taille) pour les trois opérations (insertion, suppression, recherche) lorsqu'elle est codée en structure de liste.
Il est néanmoins à observer que lorsque les données ne sont pas triées, l'insertion en tête ou fin de liste, ainsi que la suppression se font en temps constant.
