
- Accueil
- Programmation Web S2
- Objectifs de la séance
- Introduction
- Versionnage du projet
- Notion d'adresse Web
- Échanges HTTP
- Messages HTTP
- Cookies et sessions
- Échanges HTTP et PHP en mode serveur
Objectifs de la séance ¶
- Se familiariser avec les éléments mis en œuvre entre le moment de la saisie d'une URL dans le navigateur et l'affichage du résultat
- Découvrir la notion d'URI, d'URL
- Utiliser la barre de développement du navigateur Web
- Observer les échanges client/serveur avec protocole HTTP
- Découvrir la structure des messages HTTP
- Découvrir les en-têtes HTTP
- Comprendre le contenu des messages HTTP
- Comprendre les relations entre les formulaires GET ou POST et les requêtes HTTP construites
- Écrire des requêtes HTTP
- Effectuer des requêtes HTTP en ligne de commande
- Écrire des requêtes HTTP portant des données
- Comprendre les requêtes conditionnelles et leur utilité pour la gestion du cache
Introduction ¶
Le protocole HTTP (Hypertext Transfer Protocol) est un protocole d'échange client-serveur de la couche application du modèle OSI. Il a été conçu dans les années 1990 pour répondre à la mise à disposition de ressources sur le World Wide Web. Ces ressources sont hébergées sur des serveurs Web (également appelés serveurs HTTP) et peuvent être récupérées à l'aide des URI et consultées sur les navigateurs Web (tels que Chrome, Firefox, Opera ou Edge pour les plus connus) mais également par les robots d'indexation des moteurs de recherche qui explorent et indexent le Web. La navigation entre les ressources est rendue possible par les hyperliens (ou liens hypertextes).
L'objectif de ce TP est de vous familiariser avec les notions d'URI, de comprendre en détail les échanges ainsi que le protocole HTTP et de réaliser vous-même des requêtes HTTP. Cette bonne connaissance de la mécanique HTTP vous permettra d'aborder sereinement la programmation Web proposée en B.U.T., côté serveur en PHP comme côté client en JavaScript.
Ce TP ne sera pas directement évalué, mais il vous est demandé de consigner vos réponses dans un dépôt Git qui vous sera utile lors de vos révisions.
Versionnage du projet ¶
Pour ce sujet de TP, vous créerez un nouveau répertoire, vous initialiserez un dépôt Git dans ce répertoire et créerez un dépôt distant sur GitLab. Vous réaliserez une opération de validation avec git commit au moins une fois par question du sujet.
Initialisation du dépôt ¶
- Ouvrez un terminal puis utilisez la commande
mkdir un_nom_de_répertoirepour créer un nouveau répertoire «protocole-http» dans «$HOME» suivie de la commandecd un_chemin_relatif_ou_absolupour vous placer dans le répertoire - Initialisez le dépôt Git du projet
git init
- Effectuez une première validation
git commit --allow-empty -m "Initial commit"
- Éditez le fichier «
.gitignore» pour exclure les fichiers binaires inutiles à votre projet (fichierspptxdu cours, …), les fichiers qui contiennent des mots de passe ou, dans le cas des projets collaboratifs, les fichiers créés par votre éditeur de texte (répertoire «.idea» pourPhpStorm) - Éditez un fichier «
README.md» dans lequel doivent figurer :- un titre de niveau 1 contenant le titre explicite du projet
- un titre de niveau 2 « Auteur(s) » vous permettant de préciser votre nom et votre prénom (ainsi que ceux de votre binôme, le cas échéant)
- un titre de niveau 2 « Installation / Configuration » précisant les points essentiels permettant d'installer, de configurer et de lancer le projet
- Ajoutez les fichiers au dépôt
git add .
- Effectuez une nouvelle validation
git commit -m "Repository setup"
- Si nécessaire, renommez la branche principale en «
main» (une branche vide ne peut pas être renommée, c'est pourquoi ceci est fait après le premiercommit)git branch -m main
Notez que vous pouvez le faire de façon définitive avec la commande suivante, à condition d'utilisergitdans une version supérieure à2.28git config --global init.defaultbranch main
- Connectez-vous à l'application GitLab et créez un dépôt portant le même nom que votre nouveau répertoire en pensant à décocher la case « Initialize repository with a README »
- Accordez la permission «
Reporter» à votre enseignant de TP/TD - Associez le dépôt local et le dépôt distant
git remote add origin https://iut-info.univ-reims.fr/gitlab/votre_login/protocole-http.git
- Poussez le dépôt local vers le dépôt distant
git push -u origin main
Consignes ¶
- Vous effectuerez une validation après chaque question.
- À la fin de chaque séance, vous effectuerez une validation. Si cette validation contient du code incomplet ou ne fonctionnant pas, mentionnez-le dans le message de validation. Vous pousserez ensuite votre travail vers le dépôt distant.
- Ce dépôt sera utilisé par votre enseignant(e) de TP pour évaluer votre travail, que cela conduise à un note ou pas. Assurez-vous donc régulièrement que tous les fichiers que vous souhaitez lui rendre sont bien présents dans le dépôt. Respectez les noms des fichiers qui vous sont demandés si des consignes particulières vous sont données.
- Le dépôt lui-même sera évalué, soignez l'écriture de vos messages : clarté, pertinence, orthographe.
L'aide-mémoire Git et l'aide-mémoire GitLab de Monsieur Nourrit pourront vous être utiles.
Notion d'adresse Web ¶
Les URI (Universal Ressource Identifier) sont un moyen d'identifier des ressources, comme le décrit la RFC 2396. Les URI sont une généralisation des URL (Universal Ressource Locator), permettant de localiser une ressource sous la forme de ce que nous appelons communément une adresse Web.
La structure des URI, dont la syntaxe dépend du protocole, est la suivante :
Le diagramme précédent est celui de la syntaxe d'une URI, son principe est repris en texte ci-après.
Le diagramme précédent peut être exprimé sous une forme texte dans laquelle les éléments entre crochets sont facultatifs :
scheme ":" ["//" authority] path ["?" query] ["#" fragment]la partie authority, facultative, étant décomposée en :
[userinfo "@"] host [":" port]
Détaillons les divers éléments constitutifs des URI.
schemereprésente le schéma de l'URI (protocole au sens large) :httphttpsftpnewsmailtofiletel- …
authorityregroupe l'ensemble des informations nécessaires à la connexion :userinfoqui est composé deusernameetpassword, séparés par «:» et suivis de «@»john@john:easypassword@
hostpermet de désigner le nom DNS de l'hôte, son adresse IP v4 (sous la forme «A.B.C.D») ou son adresse IP v6 (entre crochets «[…]»)intranetiut-info.univ-reims.frwww.imperial.ac.ukexample.com93.184.216.34[2606:2800:220:1:248:1893:25c8:1946]
port, précédé de «:», vous permet de spécifier le port réseau804432225565- …
pathdécrit le chemin de la ressource dans lequel les segments sont séparés par des «/» (slash)//index.php/users/cutrona/restricted/but/protocole-http/img/URI_syntax_diagram.svg- …
Remarque importanteCe chemin ne désigne pas nécessairement un fichier stocké sur le serveur.
queryest la « query string », c'est-à-dire la chaîne de requête, commençant par «?», qui contient des données regroupées en un ensemble de couples «parameterName=encodedValue» séparés par «&»?a=12?action=logout?firstname=John&lastname=Doe?darkmode&theme=green(il n'y a pas nécessairement de valeur comme pour le paramètredarkmode)- …
Remarque importanteLa partie
queryde l'URI correspond à des données qui vont implicitement passer du client au serveur interrogé.Les valeurs des paramètres doivent nécessairement être encodées pour que les caractères n'entrent pas en conflit avec ceux utilisés dans les URI («
#», «&», «:», …)fragment(identificateur de fragment en français) désigne une ressource subordonnée de la ressource primaire, classiquement un élément identifié dans un document HTML
Travail à réaliser
- Trouvez la syntaxe des
URIpermettant :- d'envoyer un mail (mais ne l'envoyez pas !) avec sujet du mail fourni (Ex : mail à
jerome.cutrona@univ-reims.fravec le sujetJ'aime le Web) - d'accéder à un répertoire partagé par un serveur ftp en anonyme (Ex :
ftp.sunet.seouftp.proxad.net) - d'accéder à un répertoire local sur votre poste de travail (Ex :
/tmpsur Linux)
- d'envoyer un mail (mais ne l'envoyez pas !) avec sujet du mail fourni (Ex : mail à
- Donnez les valeurs des éléments constitutifs des
URIqui suivent :https://example.com/https://www.iut-rcc.fr/media-files/30677/but-info.pdfhttps://iut-info.univ-reims.fr/users/cutrona/intranet/installation-configuration/ubuntu-opennebula/index.html#objectifs-de-la-seancehttp://demo.ad-urca.univ-reims.fr/?infomysql://app:!ChangeMe!@127.0.0.1:3306/app?serverVersion=8&charset=utf8mb4https://www.univ-reims.fr/formation/catalogue-de-formation/but-informatique,23515,38949.html?args=R9qFsCnMmKDtxCa17YTDkHVqaqbfYRXwwTnCVt2witCDUIiVoUdkeMDp%2AXGEGm2SMIhvMbuZ3_kOrRxvJlk6dOorIryuNioRCyFFyPAvhl9tCdwYdtHRrwAvNC1tDg_H&formation_id=17#formationDetailDecriptions
Échanges HTTP ¶
Le protocole HTTP (Hypertext Transfer Protocol) est un protocole d'échange client-serveur de la couche application. Il a été conçu dans les années 1990 pour répondre à la mise à disposition de ressources sur le World Wide Web. Ces ressources sont hébergées sur des serveurs HTTP et peuvent être récupérées et consultées à l'aide des URI.
Une interrogation HTTP classique se déroule toujours suivant ces étapes :
- Établissement d'une connexion TCP à la demande du client
- Échange HTTP :
- Envoi d'une requête HTTP au serveur par le client
- Traitement de la requête par le serveur
- Envoi d'une réponse HTTP au client par le serveur
- Fermeture de la connexion TCP à l'initiative du serveur
- Interprétation par le client de la ressource récupérée
Établir la connexion avec le serveur nécessite évidemment de connaître son adresse IP v4 ou v6. Pour cela, si l'hôte est désigné par son FQDN (Fully qualified domain name), une phase de résolution DNS sera nécessaire.
La connexion réseau se fait classiquement sur le port 80 du serveur pour les URI « http:// » et sur le port 443 pour les URI « https:// ». Ces ports peuvent naturellement être modifiés dans la configuration du serveur pour des besoins spécifiques, comme la phase de développement d'une application Web.
Les diagrammes d'échanges de ce sujet nécessitent un fichier plantuml de définition de procédures, fonctions et paramètres de configuration.
Ressources liées en HTTP 1.0 ¶
Lorsque la ressource récupérée est un contenu HTML, ce dernier est interprété par le navigateur afin de produire un rendu graphique pour l'utilisateur. Si ce contenu HTML fait référence à des feuilles de style, images, scripts JavaScript, le navigateur doit effectuer des nouvelles requêtes HTTP afin de récupérer ces ressources liées.
Dans le contexte de HTTP 1.0, le serveur ferme systématiquement la connexion réseau après avoir répondu au client. Ceci engendre des pertes de temps et de la consommation inutile de ressources pour établir de nouveau la connexion en cas de requêtes multiples sur le même serveur Web :
Ressources liées en HTTP 1.1 et plus ¶
HTTP 1.1 introduit la possibilité de demander au serveur de ne pas mettre fin à la connexion réseau, et ainsi permettre d'effectuer plusieurs échanges HTTP sur la même connexion réseau pour gagner du temps et des ressources :
Ce mécanisme est rendu possible par l'introduction de l'en-tête Connection sur lequel nous reviendrons lors de l'étude des requêtes HTTP.
Visualisation des échanges HTTP dans le navigateur ¶
Les navigateurs Web intègrent une « barre de développement » qui apportent des outils précieux pour les développeurs Web. Cette « barre de développement » propose des outils similaires sur tous les navigateurs, avec toutefois quelques variations. Nous utiliserons systématiquement Firefox afin d'illustrer les outils et ne pas avoir à chercher la localisation ou l'option équivalente sur unn autre navigateur. Vous pourrez utiliser le navigateur de votre choix dans la suite de votre cursus.
Ressource principale ¶
Observons les échanges relatés par la « barre de développement » lors de la récupération d'une ressource principale (presque) unique.
Travail à réaliser
- Si ce n'est pas déjà fait, lancez Firefox :

- En appuyant sur
F12ouCTRL+SHIFT+I, vous activez la barre de développement :
- Activez l'onglet « Réseau » de la barre de développement :

- Saisissez l'adresse
https://example.com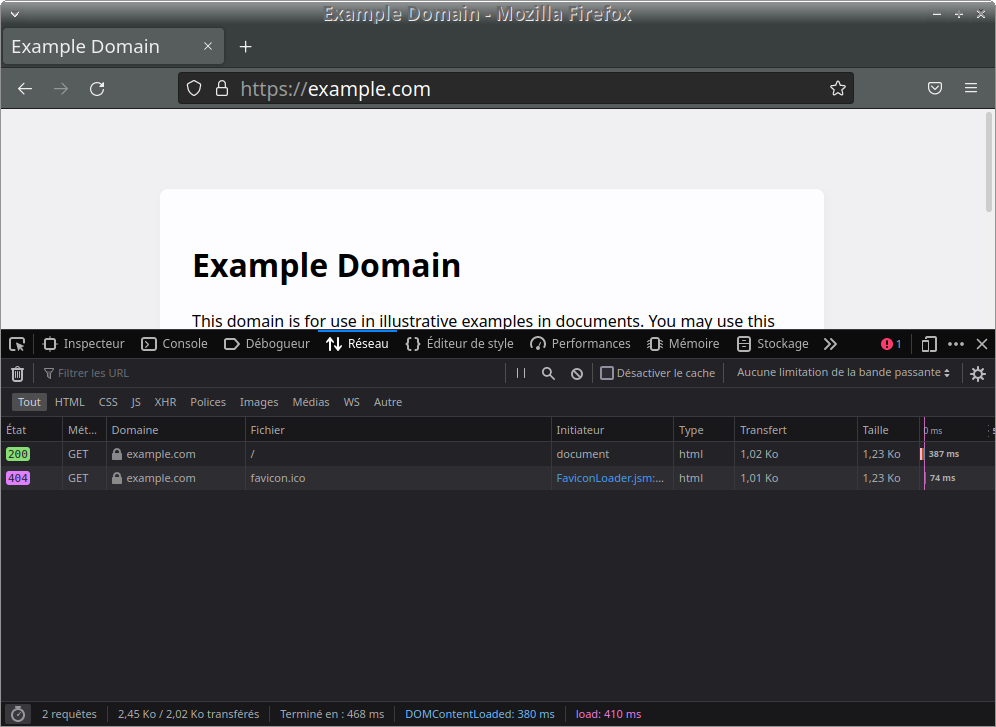
- Consultez la liste des ressources récupérées et répondez aux questions suivantes :
- Donnez le nom de la ressource principale
- Donnez la nature de la ressource principale
- Expliquez la présence de la ressource
favicon.ico
Ressources liées ¶
Observons les échanges relatés par la « barre de développement » lors de la récupération d'une ressource principale possédant des ressources liées.
Travail à réaliser
- Si ce n'est pas déjà fait, ouvrez le sujet de ce TP avec Firefox :
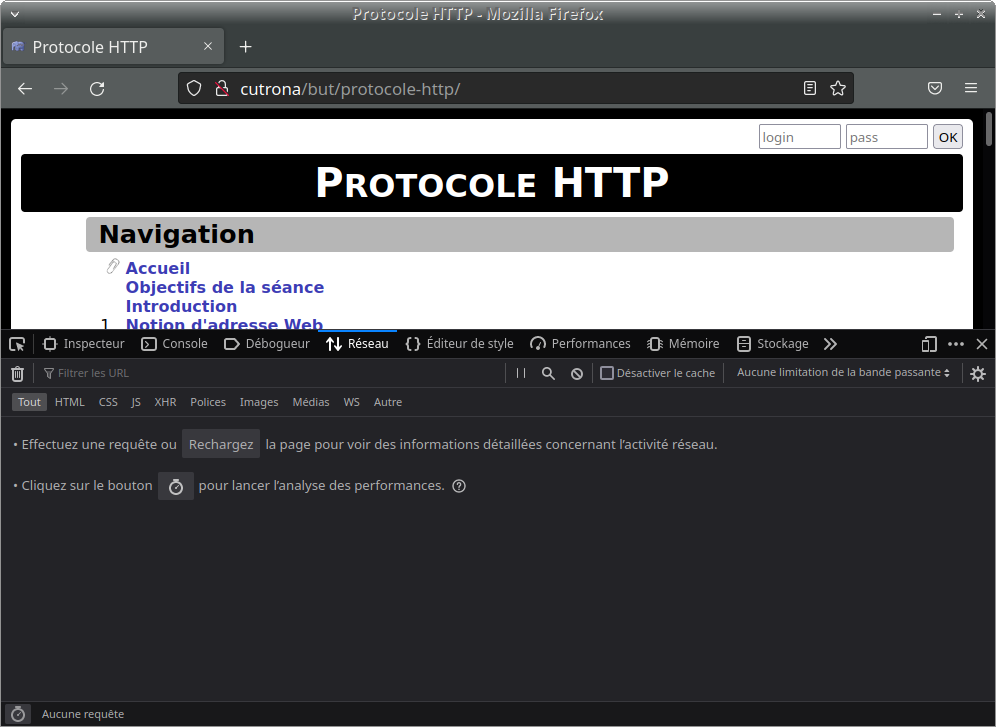
- Ouvrez la « barre de développement » et constatez l'absence d'affichage d'échanges :
- Forcez le rechargement de la page Web avec
SHIFT+F5(sauf sur Firefox),SHIFT+CTRL+Rou le bouton « actualiser » en maintenant SHIFT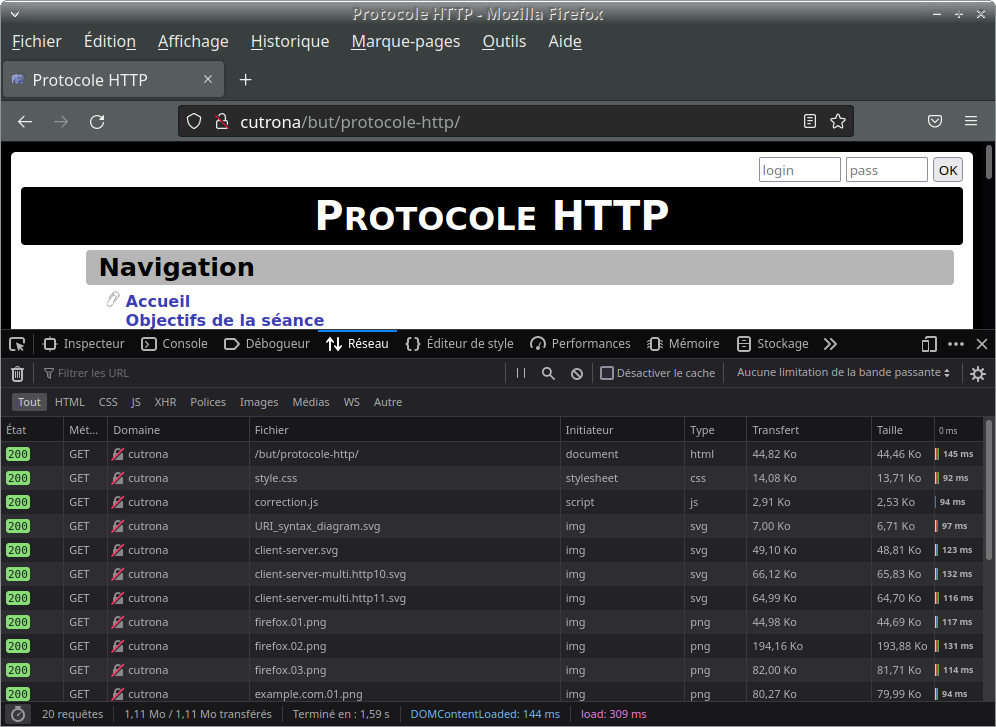
- En consultant la liste des ressources récupérées ainsi que leur contenu (vous pouvez consulter le code source de la page web et utiliser « l'inspecteur du style et du DOM » de Firefox), expliquez pourquoi les ressources suivantes sont demandées au serveur :
- «
style.css» - «
correction.js» - «
URI_syntax_diagram.svg» - «
timer.png»
- «
Messages HTTP ¶
Jusqu'à présent, nous avons observé le dialogue entre le client et le serveur sans entrer dans le détail des messages échangés. La compréhension du contenu de ces messages permet de mieux comprendre le dialogue et poser des bases solides pour vos futurs développements Web. De manière générale, un dialogue HTTP consiste en l'échange d'un message HTTP de type requête envoyé par le client, auquel le serveur répond avec un message HTTP de type réponse à destination du client.
Les messages HTTP sont composés de texte structuré en lignes. Ceci signifie que chaque ligne a un sens particulier. La structure d'un message HTTP, de type requête comme de type réponse, est découpée ainsi :
- Une ligne de requête (pour la requête) ou d'état (pour la réponse)
- Plusieurs lignes d'en-tête facultatives
- Une ligne sans aucun caractère (hormis le retour à la ligne)
- Un corps de requête facultatif appelé charge utile (payload en anglais)
La structure globale est donc :
Remarque importante
Le symbole « » représente ici le « retour à la ligne », volontairement mis en évidence dans tout le message sauf la charge utile (payload).
Les messages, requête et réponse, peuvent être replacés dans la globalité de l'échange entre le client et le serveur :
Requête HTTP ¶
La première ligne de la requête HTTP est composée de 3 parties :
method path version
method(méthode ou verbe HTTP) est classiquementGET,POSTouHEAD(mais aussiPUT,DELETEouPATCHpour les API Web) et correspond à l'opération que le client souhaite effectuerpathest l'URL de la ressource dont les éléments déductibles sont retirés en fonction du contexte, c'est-à-dire le protocole, l'hôte et port puisque la connexion est déjà établieversionestHTTP/1.0ouHTTP/1.1(HTTP/2 et HTTP/3 modifient le transport des données, mais pas la structure des messages)
GET / HTTP/1.0POST /login HTTP/1.1GET /register.php?firstname=John&lastname=Doe HTTP/1.1HEAD /avatar.png HTTP/1.1- …
Cette première ligne peut être suivie d'informations relatives à la requête, les en-têtes HTTP :
- en-tête général : concerne l'échange, la requête
Connection: closeCache-Control: no-cache
- en-tête de requête : précisions sur la requête ou le client
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36Host: example.comAccept-Language: fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7Cookie: UserID=JohnDoe
- en-tête d'entité : précisions sur les données envoyées dans le corps du message (payload)
Content-Length: 42Content-Type: multipart/form-data; boundary=----WebKitFormBoundary37htlZnm5RVOvzxr
Le corps de la requête, utilisé en méthode POST, peut fournir :
- la partie interrogative (la « query string »)
- la partie interrogative et des fichiers à envoyer au serveur (méthode
POSTet contenu du corpsmultipart/form-data)
Remarque importante
Si la charge utile est non vide, l'en-tête Content-Type doit impérativement être présent pour que le serveur qui reçoit le contenu connaisse la nature de ce contenu afin de pouvoir l'interprêter correctement.
Le message HTTP qui suit est une requête envoyée l'hôte « example.com », utilisant la methode « GET » pour demander la ressource « / » :
Visualisation des requêtes HTTP ¶
Maintenant que vous êtes conscient des échanges HTTP et de la structure des requêtes HTTP, vous allez observer des requêtes en fonction du navigateur et de la manière d'interroger le serveur. Pour cela, vous utiliserez, de manière directe ou indirecte, la ressource http://demo.ad-urca.univ-reims.fr/request/dump/ qui affiche la requête HTTP brute reçue par le serveur.
Travail à réaliser
- Visualisez la requête envoyée par
Firefoxen demandant l'adressehttp://demo.ad-urca.univ-reims.fr/request/dump/. - Observez la requête et expliquez tous ses éléments constitutifs
- Actualisez la page avec
SHIFT+F5(sauf sur Firefox),SHIFT+CTRL+Rou le bouton « actualiser » en maintenant SHIFT - Observez et expliquez les changements dans la requête transmise au serveur
- Actualisez la page avec
F5,CTRL+Rou le bouton « actualiser » - Observez et expliquez les changements dans la requête transmise au serveur
- Activez l'onglet « Réseau » de la barre de développement
- Cochez la case « Désactiver le cache »
- Actualisez la page avec
,CTRL+Rou le bouton « actualiser » - Observez et expliquez les changements dans la requête transmise au serveur
- Décochez la case « Désactiver le cache »
Les précédentes observations ne concernent qu'une requête GET et sans « query string », c'est-à-dire sans paramètre. Vous allez maintenant tester divers cas de figure en utilisant comme point de départ la page Web http://demo.ad-urca.univ-reims.fr/request/.
Requête depuis un lien ¶
Travail à réaliser
- Dans un nouvel onglet de
Firefox, saisissez l'adressehttp://demo.ad-urca.univ-reims.fr/request/dans la barre d'adresse - Ouvrez la « barre de développement »
- Cliquez sur le lien « Cliquez ici » de l'ensemble « …depuis un lien »
- Observez la requête, trouvez l'en-tête nouveau par rapport aux questions précédentes et expliquez son utilité
Requête depuis un formulaire en méthode GET ¶
Travail à réaliser
- Revenez sur la page
http://demo.ad-urca.univ-reims.fr/request/ - Observez le formulaire de l'ensemble « …depuis un formulaire en méthode GET » (visuel et code source HTML)
- Donnez l'endroit où est indiquée la méthode HTTP utilisée par ce formulaire
- Soumettez ce formulaire
- Cherchez les relations entre, d'un côté les champs et valeurs choisies dans le formulaire et, de l'autre côté la requête HTTP
- Revenez sur le formulaire et cliquez sur le bouton « ou ne pas soumettre »
- Cherchez les différences avec la précédente requête
- Revenez sur le formulaire et essayez diverses combinaisons de saisie (bouton radio coché ou pas) et observez l'impact sur la requête HTTP
Requête depuis un lien avec des paramètres ¶
Travail à réaliser
- Revenez sur la page
http://demo.ad-urca.univ-reims.fr/request/ - Cliquez sur le lien « Cliquez ici » de l'ensemble « …depuis un lien avec des paramètres »
- Cherchez les relations entre, d'un côté la requête HTTP de la question précédente et, de l'autre côté l'URL sur laquelle vous venez de cliquer et la requête HTTP que cela engendre
Requête depuis un formulaire en méthode POST ¶
Travail à réaliser
- Revenez une nouvelle fois sur la page
http://demo.ad-urca.univ-reims.fr/request/ - Observez le formulaire de l'ensemble « …depuis un formulaire en méthode POST » (visuel et code source HTML)
- Donnez l'endroit où est précisée méthode HTTP utilisée par ce formulaire
- Soumettez ce formulaire
- Expliquez la présence de l'entête de requête
Content-Type - Cherchez les relations entre, d'un côté les champs et valeurs choisies dans le formulaire et, de l'autre côté la requête HTTP
- Donnez les différences avec la même requête HTTP mais selon la méthode GET
Requête depuis un formulaire en méthode POST contenant un champ de type fichier ¶
Travail à réaliser
- Revenez une dernière fois sur la page
http://demo.ad-urca.univ-reims.fr/request/ - Observez le formulaire de l'ensemble « …depuis un formulaire en méthode POST contenant un champ fichier » (visuel et code source HTML)
- Trouvez une nouveauté concernant la balise
<form> - Trouvez le nouveau champ par rapport au précédent formulaire
- Soumettez ce formulaire sans avoir sélectionné de fichier
- Cherchez les relations entre, d'un côté les champs et valeurs choisies dans le formulaire et, de l'autre côté la requête HTTP
- Expliquez la présence de l'entête de requête
Content-Type - Expliquez la présence de
boundary=…dans l'entête de requêteContent-Type - Expliquez la structure complexe de la charge utile de la requête
- Soumettez ce formulaire après avoir sélectionné un fichier de petite taille
- Cherchez les relations entre, d'un côté les champs et valeurs choisies dans le formulaire et, de l'autre côté la requête HTTP
Réponse HTTP ¶
La première ligne de la réponse HTTP est composée de 3 parties :
"HTTP/"version status_code status_message
versionvaut1.0ou1.1(HTTP/2 et HTTP/3 modifient le transport des données, mais pas la structure des messages)status_codeest le code d'état de la réponse sur 3 chiffresstatus_messageest le message typique associé au code précédent (n'importe quel message lisible par un humain peut être fourni)
HTTP/1.0 200 OKHTTP/1.1 301 Moved PermanentlyHTTP/1.1 404 Not FoundHTTP/1.1 500 Internal Server Error- …
Les codes d'état de réponse sont regroupés en fonction du premier chiffre :
1xx: informationHTTP/1.1 100 Continue
2xx: succèsHTTP/1.0 200 OKHTTP/1.1 201 Created- …
3xx: redirectionHTTP/1.1 301 Moved PermanentlyHTTP/1.1 302 FoundHTTP/1.1 304 Not Modified- …
4xx: erreur du clientHTTP/1.1 400 Bad RequestHTTP/1.1 403 ForbiddenHTTP/1.1 404 Not FoundHTTP/1.1 418 I'm a teapot- …
5xx: erreur du serveurHTTP/1.1 500 Internal Server ErrorHTTP/1.1 501 Not ImplementedHTTP/1.1 503 Service Unavailable- …
La ligne de statut de la réponse est suivie, comme dans tout message HTTP, d'éventuels en-têtes, d'une ligne vide et possiblement d'un corps de réponse. Tout comme dans les requêtes HTTP, les en-têtes de réponse HTTP peuvent être regroupés en :
- en-tête général : concerne l'échange, la requête
Connection: closeCache-Control: no-cache
- en-tête de réponse : précisions sur la réponse ou le serveur
Location: /loginServer: Apache/2.4.6 (CentOS) OpenSSL/1.0.2k-fips PHP/8.0.13Set-Cookie: UserID=JohnDoe; Max-Age=3600
- en-tête de l'entité : précisions sur les données envoyées dans le corps du message (payload)
Content-Length: 52Content-Type: text/html; charset=utf-8Content-Disposition: attachment; filename="bill.pdf"Last-Modified: Mon, 24 Jan 2022 12:41:42 GMT
Le corps de la réponse, contient possiblement la ressource demandée par le client.
Remarque importante
Si la charge utile est non vide, l'en-tête Content-Type doit impérativement être présent pour que le client qui reçoit le contenu connaisse la nature de ce contenu afin de pouvoir l'interprêter correctement.
Suite à cette requête vue dans la partie précédente, le serveur a transmis cette réponse HTTP dont le corps (payload) a été tronqué :
Outil d'interrogation HTTP en ligne de commande ¶
Habituellement, les agents utilisateurs (user agents) qui interrogent les sites Web sont les navigateurs Web, les robots d'indexation des moteurs de recherche ou encore les lecteurs d'écran ou les navigateurs en accessibility. Votre navigateur vous permet de :
- effectuer la connexion TCP sur l'adresse IP du serveur Web identifié dans l'URL saisie dans la barre d'adresse
- formuler la requête HTTP et de l'envoyer au serveur Web
- récupérer la réponse HTTP envoyée par le serveur Web
- décoder le contenu de la réponse HTTP pour en faire un rendu graphique
L'objectif étant ici d'étudier le protocole, les échanges et les messages HTTP, vous allez utiliser un outil en ligne de commande qui permet de :
- effectuer la connexion TCP sur l'adresse IP du serveur Web dont le nom est fourni en paramètre de la ligne de commande
- envoyer au serveur Web la requête HTTP que vous aurez formulée dans un fichier désigné en paramètre de la ligne de commande
- récupérer la réponse HTTP envoyée par le serveur Web
- afficher dans le terminal le contenu brut de la réponse HTTP
Cet outil en ligne de commande, écrit en PHP et développé en interne, s'utilise de la façon suivante :
http [--secure] --host host --port port file
--secureest une option facultative pour effectuer une connexion sécurisée sur le serveur (pour HTTPS)--host hostpermet de donner le nom ou l'adresse IP du serveur sur lequel vous souhaitez vous connecter--port portpermet de donner le port du serveur sur lequel vous souhaitez vous connecterfilecorrespond au nom du fichier contenant la requête HTTP complète que vous souhaitez soumettre au serveur
Mise en place de l'outil ¶
Afin de pouvoir utiliser l'outil quel que soit votre répertoire de travail, vous allez placer le script dans un répertoire bin à la racine de votre compte et ajouter ce chemin à la variable d'environnement PATH. Cette démarche est très classique et sera réutilisée dans d'autres TP tout au long de votre formation.
Travail à réaliser
- Ouvrez un terminal
- S'il n'existe pas, créez un répertoire
bindans votre répertoire d'accueil :mkdir ~/bin
- Placez-vous dans le répertoire
binvotre répertoire d'accueil :cd ~/bin
- Si vous ne l'avez pas déjà fait, ajoutez le répertoire
~/binà la variablePATHen modifiant le fichier~/.bashrcpour y insérer la ligne suivante :export PATH="$HOME/bin:$PATH"
- Si vous avez modifié le script shell
~/.bashrc, rechargez-le dans votre environnement en passant la commande :source ~/.bashrc
- Vérifiez la présence du chemin correspondant à
~/bindans la variablePATHen passant la commande :echo $PATH
- Récupérez le script de l'outil d'interrogation HTTP en utilisant « enregistrer sous »
- Placez le script dans le répertoire
~/bin - Rendez le script exécutable à l'aide de
setfacl:setfacl -m u::rwx ~/bin/http
- Placez-vous dans le répertoire de votre projet :
cd chemin_relatif_ou_absolu/protocole-http
- Vérifiez le bon fonctionnement en passant la commande :
http
qui devrait produire cette sortie :USAGE: http --host|-h host --port|-p port [--secure|-s] file ERROR: missing parameters
Première utilisation de l'outil ¶
À titre d'exemple, vous allez interroger le site http://example.com.
Remarque importante
Tous les fichiers contenant des requêtes HTTP seront placés dans un répertoire requests que vous créerez dans votre projet versionné.
Travail à réaliser
- Créez un répertoire
requestsdans votre projet - Récupérez le fichier
example.com-get-root.txten utilisant « enregistrer sous » - Placez le fichier dans le répertoire
requestsde votre projet - Consultez le contenu de ce fichier
- Lancez la commande
http --host example.com --port 80 requests/example.com-get-root.txt
- Observez l'affichage produit par cette commande :
REQUEST: 1: GET / HTTP/1.1 2: Host: example.com 3: Connection: close 4: -------------------------------------------------------------------------------- RESPONSE: HTTP/1.1 200 OK Age: 508025 Cache-Control: max-age=604800 Content-Type: text/html; charset=UTF-8 Date: Tue, 18 Jan 2022 22:08:16 GMT Etag: "3147526947+ident" Expires: Tue, 25 Jan 2022 22:08:16 GMT Last-Modified: Thu, 17 Oct 2019 07:18:26 GMT Server: ECS (bsa/EB11) Vary: Accept-Encoding X-Cache: HIT Content-Length: 1256 Connection: close <!doctype html> <html> <head> <title>Example Domain</title> <meta charset="utf-8" /> <meta http-equiv="Content-type" content="text/html; charset=utf-8" /> <meta name="viewport" content="width=device-width, initial-scale=1" /> <style type="text/css"> body { background-color: #f0f0f2; margin: 0; padding: 0; font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif; } div { width: 600px; margin: 5em auto; padding: 2em; background-color: #fdfdff; border-radius: 0.5em; box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02); } a:link, a:visited { color: #38488f; text-decoration: none; } @media (max-width: 700px) { div { margin: 0 auto; width: auto; } } </style> </head> <body> <div> <h1>Example Domain</h1> <p>This domain is for use in illustrative examples in documents. You may use this domain in literature without prior coordination or asking for permission.</p> <p><a href="https://www.iana.org/domains/example">More information...</a></p> </div> </body> </html> connection closed
- Repérez la requête et la réponse dans l'affichage
- Distinguez les 4 parties de la requête
- Distinguez les 4 parties de la réponse
- Effectuez la même requête en utilisant HTTPS Information
Les services réseau HTTP et HTTPS sont différents, ils sont donc fournis par le serveur sur des ports différents.
- Déterminez à quoi correspondent les en-têtes de réponse suivants ainsi que la signification des valeurs qui leur sont associées :
Content-TypeLast-ModifiedContent-Length
Quand un serveur Web est plusieurs serveurs Web ¶
Principe en HTTP 1.0 ¶
La version 1.0 du protocole HTTP permet d'envoyer une requête au serveur Web sur lequel le client est connecté en TCP sur le port 80. L'adresse IP du serveur est déterminée par le client grâce à une résolution DNS avant de tenter la connexion. Ce mécanisme implique que ce serveur Web est unique :
La résolution DNS et la connexion au serveur reviennent donc à n'utiliser que l'adresse IP du serveur sur le client :
Principe en HTTP 1.1 ¶
La version 1.1 du protocole permet d'héberger plusieurs serveurs Web sur le même serveur Web. Cette proposition semble irréalisable, mais elle est rendue possible par l'introduction d'un en-tête Host qui permet de préciser, dans la requête HTTP, l'hôte auquel le message de requête est destiné. Ce principe sous-entend que l'hôte (le serveur possédant une adresse IP) hébergeant le serveur Web peut héberger d'autres serveurs Web sur la même adresse IP et sur le même port réseau.
Étudions dans un premier temps les relations entre nom DNS et adresse IP (ces manipulations fonctionnent uniquement dans le réseau du département informatique ou dans son VPN) :
Travail à réaliser
- Ouvrez un terminal
- Déterminez l'adresse IP de mon serveur Web dont le nom DNS est
cutronaà l'aide de la commandehost:host cutrona cutrona.ad-urca.univ-reims.fr is an alias for cutron01.ad-urca.univ-reims.fr. cutron01.ad-urca.univ-reims.fr is an alias for web-prod.ad-urca.univ-reims.fr. web-prod.ad-urca.univ-reims.fr is an alias for node016.ad-urca.univ-reims.fr. node016.ad-urca.univ-reims.fr has address 10.31.6.118
- Constatez que
cutronaest en réalitécutrona.ad-urca.univ-reims.frcar les machines du département informatique sont dans le domaine DNSad-urca.univ-reims.fr - Constatez les divers alias DNS et l'adresse IP associée à
cutrona - Déterminez l'adresse IP du serveur Web de M. Arganini dont le nom DNS est
arganini - Déterminez l'adresse IP du serveur Web de M. Jonquet dont le nom DNS est
jonquet - Déterminez l'adresse IP du serveur Web de votre propre serveur Web dont le nom DNS est
votre_login - Utilisez votre navigateur pour interroger, directement avec son adresse IP v4, le serveur Web dont vous venez de déterminer l'adresse IP v4
Vous venez de constater que les ressources Web de tous les enseignants et étudiants du département informatique sont portées par le même serveur dont l'adresse IP v4 est 10.31.6.118. Dans ces conditions, une fois votre navigateur connecté sur le port 80 de 10.31.6.118, une requête HTTP demandant la ressource « / » est nécessairement indéterminée puisque le serveur possède autant de ressources « / » que de serveurs d'hébergement Web virtuel. Il est donc impératif que la requête contienne le nom DNS du serveur d'hébergement Web virtuel qui doit être réellement sollicité. C'est le but de l'en-tête Host.
Interrogation HTTP en ligne de commande ¶
Afin de vous rendre compte des échanges de messages HTTP, vous allez utiliser l'outil d'interrogation HTTP en ligne de commande vu plus tôt pour effectuer diverses requêtes HTTP et prendre connaissance des réponses HTTP fournies par le serveur interrogé.
Remarque importante
Dans une requête HTTP, vous aurez sans nul doute noté l'importance de la ligne contenant uniquement un retour à la ligne qui marque la fin des en-têtes. Afin de prendre conscience de la présence ou non de cette ligne fondamentale dans vos requêtes, vous devriez systématiquement afficher les numéros de lignes dans votre éditeur de texte.
Requête HTTP 1.0 sur le serveur 10.31.6.118
¶
Travail à réaliser
- Écrivez dans le fichier
requests/10.31.6.118-get-http10.txtla requête HTTP 1.0 demandant la ressource «/» au serveur10.31.6.118 - Soumettez la requête au serveur
- Donnez le code d'état de la réponse HTTP
- Lisez le code HTML contenu dans la charge utile de la réponse HTTP pour comprendre le sens de ce code d'état
- Donnez le type et la version du serveur Web
- Donnez le système d'exploitation annoncé par le serveur
Requête HTTP 1.0 sur le serveur cutrona
¶
Travail à réaliser
- Effectuez la requête
requests/10.31.6.118-get-http10.txten vous connectant sur l'hôtecutrona - Donnez les différences avec la précédente requête
Requête HTTP 1.1 sur le serveur 10.31.6.118
¶
Travail à réaliser
- Écrivez dans le fichier
requests/10.31.6.118-get-http11.txtla requête HTTP 1.1 demandant la ressource «/» au serveur10.31.6.118 - Soumettez la requête au serveur
- Donnez le code d'état de la réponse HTTP
- Précisez à quoi correspondent les dernières lignes dans l'affichage de la commande :
waiting... waiting... waiting... waiting... waiting... connection closed
- Modifiez la requête HTTP dans un nouveau fichier
requests/10.31.6.118-get-http11-connection-close.txtafin que le serveur n'attende plus avant de couper la connexion - Effectuez la nouvelle requête
requests/10.31.6.118-get-http11-connection-close.txten vous connectant sur l'hôte10.31.6.118 - Constatez la présence d'un nouvel en-tête dans lé réponse du serveur Remarque importante
Puisque l'outil d'interrogation HTTP en ligne de commande est prévu pour n'effectuer qu'une seule requête, vous utiliserez à présent systématiquement l'en-tête
Connection: closedans vos requêtes. - Utilisez votre navigateur pour accéder au serveur Web
10.31.6.118 - Observez les échanges réseau entre votre navigateur et le serveur Web
- Expliquez la présence de ressources liées à la ressource principale
Requête HTTP 1.1 sur le serveur demo.ad-urca.univ-reims.fr
¶
Travail à réaliser
- Écrivez dans le fichier
requests/demo-get-bonjour.html.txtla requête HTTP demandant la ressource «http://demo.ad-urca.univ-reims.fr/bonjour.html» - Soumettez la requête au serveur
- Écrivez dans le fichier
requests/demo-post-bonjour.html.txtla requête HTTP demandant la ressource «http://demo.ad-urca.univ-reims.fr/bonjour.html» selon la méthodePOST - Soumettez la requête au serveur
- Observez les deux réponses précédentes du serveur pour distinguer des similitudes et/ou des différences
- Écrivez dans le fichier
requests/demo-get-query-string-bip-nb.txtla requête HTTP demandant la ressource «http://demo.ad-urca.univ-reims.fr/query-string/» selon la méthodeGETet en passant les paramètres de requête «bip» valant «meuh, meuh & meuh» ainsi que «nb» valant «12» - Soumettez la requête au serveur
- Écrivez dans le fichier
requests/demo-post-query-string-bip-nb.txtla requête HTTP demandant la ressource «http://demo.ad-urca.univ-reims.fr/query-string/» selon la méthodePOSTet en passant les paramètres de requête «bip» valant «meuh, meuh & meuh» ainsi que «nb» valant «12» - Soumettez la requête au serveur
- Distinguer des similitudes et/ou des différences entre la requête faite avec la méthode
GETet celle faite avec la méthodePOST
Requête HTTP et gestion du cache ¶
Travail à réaliser
- Lisez la documentation des cas d'utilisation des requêtes conditionnelles en ne tenant pas compte de l'en-tête
ETagque nous n'utiliserons pas. - Ouvrez de nouveau la requête HTTP
requests/demo-get-bonjour.html.txtdemandant la ressource «http://demo.ad-urca.univ-reims.fr/bonjour.html» - Soumettez la requête au serveur
- Cherchez l'en-tête donnant la date de dernière modification de la ressource
- Écrivez dans le fichier
requests/demo-get-bonjour.html-if-modified-since.txtla requête HTTP demandant la ressource «http://demo.ad-urca.univ-reims.fr/bonjour.html» uniquement si elle est modifiée depuis une date postérieure à celle constatée dans la question précédente - Soumettez la requête au serveur
- Donnez le code d'état de la réponse HTTP (ce ne doit pas être 200 !)
Cookies et sessions ¶
Le protocole HTTP est un protocole sans état, ce qui signifie que le serveur ne conserve aucune information sur un client et n'a même aucune conscience de répondre au même client. Ceci est dû au fait que la mission du serveur est de donner une réponse à une requête, sans vision de la globalité des échanges. Dans ces conditions, il est impossible d'entrevoir la réalisation d'une application Web qui nécessite d'apporter une réponse particulière à chaque client. Heureusement, le protocole HTTP prévoit que le serveur puisse demander à un client particulier de stocker une information qu'il devra retransmettre au serveur en cas de nouvelle requête. Cette information est un cookie.
Cookies ¶
Le premier mécanisme permettant de produire des réponses spécifiques pour un client est celui des cookies. Le serveur décide de donner la responsabilité au client de lui rappeler un ensemble de valeurs. Le client qui les reçoit doit donc les retransmettre à chaque nouvelle requête sur le même serveur.
Travail à réaliser
- Accédez à http://demo.ad-urca.univ-reims.fr/cookie/ avec Firefox
- Ouvrez la barre de développement
- Cherchez des traces de cookies dans la requête et la réponse HTTP dans l'onglet « Réseau »
- Observez l'absence de cookies dans l'onglet « Stockage » (« Application » pour Chrome)
- Cliquez sur le lien pour choisir le thème « dark » ou « gray »
- Cherchez des traces de cookies dans la requête et la réponse HTTP dans l'onglet « Réseau »
- Observez les cookies dans l'onglet « Stockage » (« Application » pour Chrome)
- Donnez la durée de validité du cookie
- Cliquez sur le lien « Retour à l'accueil »
- Cherchez des traces de cookies dans la requête et la réponse HTTP dans l'onglet « Réseau »
- Actualisez la page Web
- Cherchez des traces de cookies dans la requête et la réponse HTTP dans l'onglet « Réseau »
- Fermez votre navigateur
- Accédez à http://demo.ad-urca.univ-reims.fr/cookie/ avec Firefox
- Expliquez le maintien du thème, même après fermeture du navigateur
- Cliquez sur le lien pour choisir un autre thème
- Cherchez des traces de cookies dans la requête et la réponse HTTP dans l'onglet « Réseau »
- Observez les cookies dans l'onglet « Stockage » (« Application » pour Chrome)
Vous connaissez à présent le fonctionnement d'un cookie, vous allez tenter de mesurer les conséquences de sa modification non contrôlée par le client.
Travail à réaliser
- Accédez à http://demo.ad-urca.univ-reims.fr/cookie/ avec Firefox
- Ouvrez la barre de développement
- Observez les cookies dans l'onglet « Stockage »
- Éditez la valeur du cookie en effectuant un double clic dessus
- Donnez successivement la valeur
light,grayoudarkau cookie - Validez la nouvelle valeur en appuyant sur
ENTERRemarque importanteComme vous venez de le voir, les manipulations de cookie sont facilement accessibles dans la barre de développement de Firefox. Si vous utilisez Chrome, vous devrez exécuter le code JavaScript
document.cookie='nom_cookie=valeur_cookie'dans la console JavaScript de la barre de développement pour fixer la valeur «valeur_cookie» du cookie «nom_cookie».. - Actualisez la page Web
- Constatez le changement de thème
- Cherchez des traces de cookies dans la requête et la réponse HTTP dans l'onglet « Réseau » de la barre de développement
- Donnez à présent une valeur différente de
light,grayoudarkau cookie - Actualisez la page Web
- Constatez le changement de thème
- Cherchez des traces de cookies dans la requête et la réponse HTTP dans l'onglet « Réseau » de la barre de développement
- Affichez le code source HTML de la page Web
- Cherchez les erreurs dans le code source HTML de la page Web
- Imaginez le fonctionnement interne du site ayant entrainé ces erreurs
Sessions ¶
Les cookies ont une utilité limitée quand il s'agit de mémoriser des informations volumineuses ou sensibles puisqu'elles sont stockées sur le client et que ce dernier transmet les valeurs à chaque nouvelle requête sur le serveur concerné. Vous avez découvert les sessions en cours magistral et leur capacité à stocker sur le serveur une grande quantité de données, sensibles ou non, dont le lien avec un client particulier est maintenu par un cookie de session qui identifie ledit client.
Principe ¶
Le principe du cookie vu précédemment reste valide et des données de session sont associés au client identifié par le cookie :
Travail à réaliser
- Ouvrez un nouvel onglet dans Firefox
- Activez l'onglet « Réseau » de la barre de développement
- Accédez à
http://demo.ad-urca.univ-reims.fr/session/dans cet onglet - Observez la réponse HTTP
- Donnez la durée de vie du cookie déposé par le serveur
- Mémorisez les 4 derniers caractères de la valeur du cookie de session
PHPSESSID - Identifiez-vous avec vos identifiants URCA
- Consultez votre « profil » sur ce site
- Fermez toutes les fenêtres de Firefox
- Relancez Firefox sur
http://demo.ad-urca.univ-reims.fr/session/ - Constatez que vous n'êtes plus identifié
- Vérifiez si la valeur du cookie de session
PHPSESSIDa changé - Déterminez à quoi correspond la durée de vie « Session » du cookie
- Identifiez-vous avec vos identifiants URCA
- Accédez à l'onglet « Stockage » de la barre de développement
- Mémorisez les 4 derniers caractères de la valeur du cookie de session
PHPSESSID - Supprimez le cookie de session
PHPSESSID - Rechargez la page
- Constatez que vous n'êtes plus identifié
- Accédez à l'onglet « Stockage » de la barre de développement
- Vérifiez si la valeur du cookie de session
PHPSESSIDa changé - Identifiez-vous avec vos identifiants URCA
- Vérifiez si la valeur du cookie de session
PHPSESSIDa changé
Réutilisation volontaire de cookie ¶
Le cookie de session faisant le lien entre le client et ses données de session sur le serveur, vous allez volontairement réutiliser le cookie dans un second navigateur et constater l'accès simultané à la session.
Travail à réaliser
- Dans Firefox :
- Utilisez le bouton « Se déconnecter » sur le site
http://demo.ad-urca.univ-reims.fr/session/ - Vérifiez que vous êtes bien déconnecté de votre compte sur le site
- Utilisez le bouton « Se déconnecter » sur le site
- Dans Chrome :
- Ouvrez un nouvel onglet
- Accédez à
http://demo.ad-urca.univ-reims.fr/session/ - Identifiez-vous avec vos identifiants URCA
- Accédez à l'onglet « Application » de la barre de développement
- Copiez le la valeur du cookie de session
PHPSESSID
- Dans Firefox :
- Activez l'onglet « Stockage » de la barre de développement
- Modifiez la valeur du cookie de session
PHPSESSIDpour lui donner celle copiée depuis Chrome - Rechargez la page
- Constatez que vous êtes identifié
- Consultez le profil pour vous assurer de la présence des informations personnelles
- Déconnectez-vous du site
- Dans Chrome :
- Rechargez la page
- Constatez que vous n'êtes plus identifié
- Identifiez-vous de nouveau avec vos identifiants URCA
- Dans Firefox :
- Rechargez la page
- Constatez que vous êtes également identifié
- Dans Chrome :
- Accédez à l'onglet « Application » de la barre de développement
- Supprimez le cookie de
PHPSESSID - Constatez que vous n'êtes plus identifié
- Dans Firefox :
- Constatez que vous êtes toujours identifié
Vol de cookie par Cross-Site Scripting (XSS) ¶
Toute la sécurité de l'accès aux données par le client repose sur le cookie de session, vous venez de le constater en le partageant délibérément entre vos deux navigateurs. Voyons comment un site mal conçu pour laisser s'échapper cette donnée cruciale.
La faille de sécurité repose sur le « Cross-Site Scripting (XSS) ». Vous allez vous faire dérober votre cookie de session du site http://demo.ad-urca.univ-reims.fr/session/ qui sera transmis et stocké sur le site pirate http://hacker.ad-urca.univ-reims.fr/. Le piège est un simple lien hypertexte envoyé par mail ou placé sur un site malveillant. Le site http://demo.ad-urca.univ-reims.fr/session/ comporte la faille de sécurité classique de réflexion : le site web insère, sans aucun contrôle ni modification, une donnée reçue dans la requête HTTP d'un client. Si la donnée reçue est un texte contenant <script>…</script> et que ce texte est inséré dans le code HTML de la réponse HTTP, le script JavaScript sera exécuté par le navigateur. Et si cette donnée est transmise selon la méthode HTTP GET, il est facile de construire un lien piégé.
Le diagramme qui suit récapitule les étapes d'identification de l'utilisateur suivies du vol du cookie.
À vous de vous faire voler votre cookie de session !
Travail à réaliser
- Formez un groupe de deux personnes : vous jouerez chacun le rôle la victime puis chacun le rôle du hacker en consultant les données personnelles de l'autre
- Victime, dans Chrome :
- Accédez à
http://demo.ad-urca.univ-reims.fr/session/, le site cible de l'attaque - Identifiez-vous avec vos identifiants URCA
- Accédez à l'onglet « Application » de la barre de développement
- Mémorisez les 4 derniers caractères de la valeur du cookie de session
PHPSESSID - Copiez le lien du sujet de TP (c'est le sujet de TP qui contient le lien piégé)
- Ouvrez un nouvel onglet dans Chrome
- Accédez à l'onglet « Réseau » de la barre de développement pour ce nouvel onglet
- Collez le lien du sujet de TP dans ce nouvel onglet
- Cliquez sur le lien piégé suivant dans le nouvel onglet dans Chrome pour voir le résultat piégé de recherche de « licorne » sur le site cible de l'attaque
http://demo.ad-urca.univ-reims.fr/et vous faire voler votre cookie de session au passage ! En cliquant sur ce lien, vous avez transmis un paramètre de requête contenant du code JavaScript qui a été inséré dans la page Web produite par le serveur sans aucune vérification - Observez l'URL sur laquelle vous venez de cliquer
- Donnez la valeur de la « query string »
- Décodez la valeur de
querycontenue dans la « query string » - Donnez la nature du texte décodé
- Expliquez le fonctionnement du texte décodé
- Affichez le code HTML source du résultat piégé de recherche de « licorne »
- Constatez la présence du texte correspondant à la valeur de
querydans le code source HTML (et c'est là que réside l'erreur commise par le code PHP côté serveur !) - Observez les requêtes réseau nécessaires à l'affichage du résultat piégé de recherche de « licorne »
- Constatez le chargement d'une ressource externe au site ciblé par l'attaque
- Rendez-vous sur
http://hacker.ad-urca.univ-reims.fr/ - Constatez la présence de votre cookie de session dans la base de données du site pirate
- Accédez à
- Exploitation du cookie volé par le hacker, dans Firefox :
- Rendez-vous sur
http://hacker.ad-urca.univ-reims.fr/ - Copiez la valeur du cookie de session de la personne avec laquelle vous travaillez (le site
http://hacker.ad-urca.univ-reims.fr/collecte les cookies de tous les groupes de TP, les 50 vols les plus récents sont affichés) - Accédez à
http://demo.ad-urca.univ-reims.fr/session/, le site cible de l'attaque - Vérifiez que vous n'êtes PAS identifié avec votre compte personnel et déconnectez-vous si nécessaire
- Accédez à l'onglet « Stockage » de la barre de développement de Firefox
- Modifiez le cookie de session pour lui donner la valeur du cookie volé Remarque importante
Les manipulations de cookie sont facilement accessibles dans la barre de développement de Firefox. Si vous utilisez Chrome, vous devrez exécuter le code JavaScript
document.cookie='nom_cookie=valeur_cookie'dans la console JavaScript de la barre de développement pour fixer la valeur «valeur_cookie» du cookie «nom_cookie». - Rechargez la page
- Constatez que vous êtes identifiés sous le nom de l'autre personne
- Cliquez sur le lien « Voir le profil »
- Constatez que vous pouvez naviguer avec l'identité de l'autre personne et accédez à ses informations
- Rendez-vous sur
Échanges HTTP et PHP en mode serveur ¶
Maintenant que vous maîtrisez le protocole HTTP, observons le détail des échanges lorsque la ressource demandée par le client se termine par « .php » :
Dans ce contexte, le but de PHP est de produire la réponse HTTP. Dans une version simple, lorsque le navigateur interroge le serveur pour la ressource « /hello.php », le serveur va demander au module PHP d'exécuter le code PHP contenu dans hello.php. Ce code PHP peut alors exécuter toutes les instructions souhaitées par le développeur et produire la charge utile à l'aide de echo. La réponse HTTP complète (ligne d'état de la réponse, en-têtes, ligne vide et charge utile) est construite par le moteur PHP sans intervention du développeur puis transmise au navigateur ayant envoyé la requête. Dans une version plus complexe, le développeur du code PHP peut intervenir sur l'état de la réponse HTTP à l'aide de la fonction PHP http_response_code(), modifier ou fixer des en-têtes avec la fonction PHP header(), placer des cookies avec la fonction PHP setcookie() et produire la charge utile à l'aide de echo.