Évaluation
Durée : 1 heure
Tout document autorisé
Test de Ruffier-Dickson
Le test de Ruffier-Dickson est un test physique qui permet d'évaluer l'aptitude d'une personne à la pratique sportive. Ce test peut être, par exemple, pratiqué sous le contrôle d'un médecin afin d'obtenir un certificat médical de non contre-indication à une pratique sportive.
Le test se déroule en trois étapes:
- après un repos (couché) de quelques minutes, une prise de pouls du sujet donne la valeur P0 (en pulsations par minute)
- le sujet doit ensuite se lever et effectuer 30 flexions complètes de jambes en 45 secondes, bras tendus devant lui. Le pouls P1 est pris immédiatement après
- puis le sujet s'allonge à nouveau, et exactement une minute après la fin des flexions on relève une dernière fois sa fréquence cardiaque P2
L'indice de Ruffier-Dickson Id permet de quantifier l'adaptation à l'effort. Il se calcule de la manière suivante :
Id = [ ( P1 - 70 ) + 2 × ( P2 - P0 ) ] / 10
| Intervalle | Adaptation à l'effort |
|---|---|
| Id = 0 | excellente |
| 0 < Id ≤ 2 | très bonne |
| 2 < Id ≤ 4 | bonne |
| 4 < Id ≤ 6 | moyenne |
| 6 < Id ≤ 8 | faible |
| 8 < Id ≤ 10 | très faible |
| Id > 10 | mauvaise |
Exercice 1
Écrivez un script ruffier-dickson.py qui calcule l'indice de Ruffier-Dickson à partir de
la saisie au clavier des féquences cardiaques P0, P1 et P2 et affiche une interprétation
en fonction de sa valeur.
#############################
# #
# Test de Ruffier-Dickson #
# #
#############################
P0 (ppm) ? 60
P1 (ppm) ? 80
P2 (ppm) ? 62
Id = 1.4
moyenne adaptation à l'effort
print('\n\n')
print('#############################')
print('# #')
print('# Test de Ruffier-Dickson #')
print('# #')
print('#############################')
print('\n')
p0 = float(input('P0 (ppm) ? '))
p1 = float(input('P1 (ppm) ? '))
p2 = float(input('P2 (ppm) ? '))
id = ( (p1 - 40) + 2*(p2 - p0) ) / 10
if id==0:
interpretation = 'excellente'
elif id<=2:
interpretation = 'très bonne'
elif id<=4:
interpretation = 'bonne'
elif id<=6:
interpretation = 'moyenne'
elif id<=8:
interpretation = 'faible'
elif id<=10:
interpretation = 'très faible'
else:
interpretation = 'mauvaise'
print('\nId =', id)
print(interpretation, 'adaptation à l\'effort')
Le fichier L2.xlsx contient différents relevés effectués par et sur
des étudiants de L2 STAPS.
Exercice 2
Écrivez un script l2_statistics.py qui calcule quelques statistiques descriptives
à partir des données du fichier Excel L2.xlsx.
Statistiques descriptives du fichier L2.xlsx
============================================
171 étudiants recensés
Âge moyen 19.5 ± 1.0
30 % de femmes
70 % d'hommes
54 % de licenciés en club
46 % de non licenciésimport pandas as pd
df = pd.read_excel('L2.xlsx')
total = len(df.index)
female = df[ df['Sexe'] == 'femme' ]
female_percentage = round(len(female.index) * 100 / total)
licensed = df[ df['Licencié'] == 'oui' ]
licensed_percentage = round(len(licensed.index) * 100 / total)
print('\n\nStatistiques descriptives du fichier L2.xlsx')
print('============================================\n')
print(total, 'étudiants recensés')
print('\nÂge moyen', round(df['Age'].mean(), 1), '±', round(df['Age'].std(), 1))
print()
print(female_percentage, '% de femmes')
print(100-female_percentage, '% d\'hommes')
print()
print(licensed_percentage, '% de licenciés en club')
print(100-licensed_percentage, '% de non licenciés')Exercice 3
Écrivez un script ruffier-dickson-excel.py qui, après avoir chargé le fichier L2.xlsx,
calcule l'indice de Ruffier-Dickson pour tous les étudiants et stocke le résultat dans une
nouvelle colonne nommée Id.
Le nouveau DataFrame sera sauvegardé dans un fichier Excel L2_Id.xlsx
import pandas as pd
df = pd.read_excel('L2.xlsx')
for i in df.index:
if df['P0 (ppm)'][i] < df['P1 (ppm)'][i]:
df.loc[i, 'Id'] = ( (df['P1 (ppm)'][i] - 40) + 2*(df['P2 (ppm)'][i] - df['P0 (ppm)'][i]) ) / 10
else:
df.loc[i, 'Id'] = ( (df['P0 (ppm)'][i] - 40) + 2*(df['P2 (ppm)'][i] - df['P1 (ppm)'][i]) ) / 10
writer = pd.ExcelWriter('L2_Id.xlsx', engine = 'xlsxwriter')
df.to_excel(writer, index = False)
writer.save()Exercice 4
À partir des données du fichier L2_Id.xlsx, écrivez un script
ruffier-dickson-best-worst.py
qui affiche le genre et le statut (licencié ou non) des étudiants ayant respectivement le meilleur et le pire
indice de Ruffier-Dickson.
Meilleur indice de Ruffier-Dickson : homme - 19 ans - non licencié
Pire indice de Ruffier-Dickson : femme - 21 ans - non licenciée
import pandas as pd
df = pd.read_excel('L2_Id.xlsx')
id_min = df['Id'].idxmin()
gender = df['Sexe'][id_min]
age = df['Age'][id_min]
if df['Licencié'][id_min] == 'oui':
licensed = 'licencié'
else:
licensed = 'non licencié'
if gender == 'femme':
licensed += 'e'
print('Meilleur indice de Ruffier-Dickson :', gender, '-', age, 'ans -', licensed)
id_max = df['Id'].idxmax()
gender = df['Sexe'][id_max]
age = df['Age'][id_max]
if df['Licencié'][id_max] == 'oui':
licensed = 'licencié'
else:
licensed = 'non licencié'
if gender == 'femme':
licensed += 'e'
print('Pire indice de Ruffier-Dickson :', gender, '-', age, 'ans -', licensed)Exercice 5
Pour finir, écrivez un script ruffier-dickson-mean.py
qui compare les moyennes et les écarts-types de l'indice de Ruffier-Dickson
pour les licenciés et non licenciés.
Licenciés : 9.3 ± 3.3
Non licenciés : 9.6 ± 3.2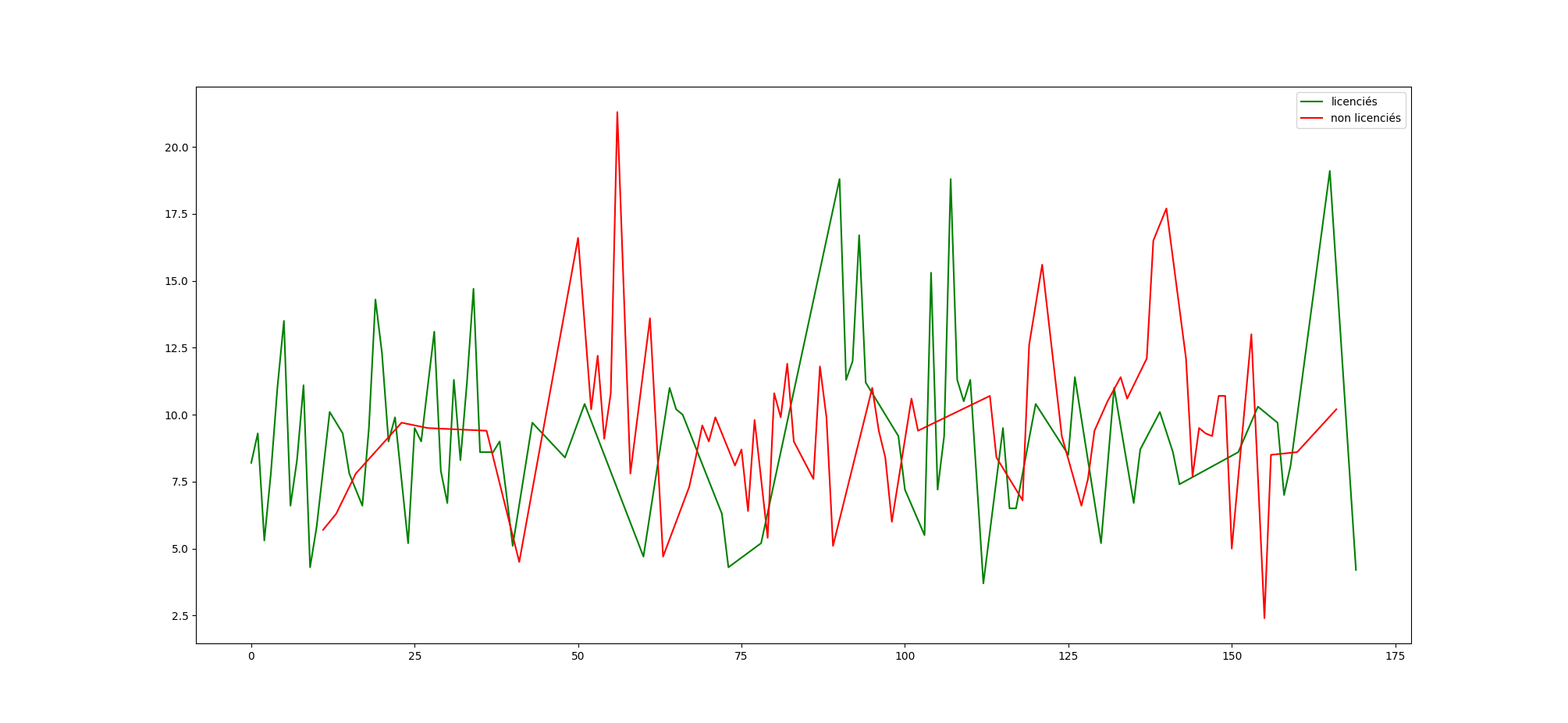
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel('L2_Id.xlsx')
licensed = df[ df['Licencié'] == 'oui' ]
non_licensed = df[ df['Licencié'] == 'non' ]
print('Licenciés :', round(licensed['Id'].mean(), 1), '±', round(licensed['Id'].std(), 1))
print('Non licenciés :', round(non_licensed['Id'].mean(), 1), '±', round(non_licensed['Id'].std(), 1))
plt.plot(licensed['Id'], 'g', label='licenciés')
plt.plot(non_licensed['Id'], 'r', label='non licenciés')
plt.legend()
plt.show()