Par exemple, cela couterait 3 millions de relier directement Zérocity à Trois-sur-marne, et 6 millions de relier directement Zérocity à Saint-Quatre.
Le regroupement de communes décide d'autoriser les changements de lignes, et de ne construire que les lignes nécessaires, afin d'assurer un coût total minimal.
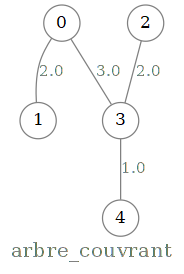
Mathématiquement, il s'agit de construire un arbre couvrant de poids minimal, c'est à dire un arbre passant par tous les sommets du graphe, dont la somme des poids des arêtes est minimale. L'algorithme proposé pour résoudre le problème est l'algorithme de Prim.
Dans l'exemple, l'arbre couvrant serait :